TL;DR
- The honest answer to the title is two answers. AI is already strong at legal output — drafting and analysis under structured conditions. It is not yet a dependable legal worker — running a matter end to end. APEX measures the first; its agent benchmark measures the second.
- APEX is the rare benchmark built the right way. Real hours-long deliverables, expert-written rubrics, eight runs per task, an open dev set, and a hidden scored set — more transparency than most legal-AI benchmarks offer.
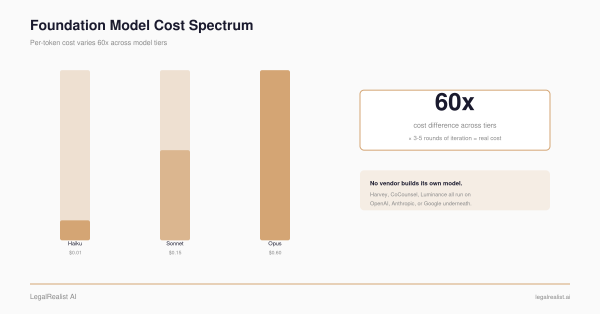
- Law was the highest-scoring domain in the December 2025 report — but only under structured conditions. The top law score was 77.9%, ahead of medicine (65.5%) and consulting (64.0%). It’s a dated snapshot; the live board has since drifted (
GPT-5now 76.6%).- When AI must act like an associate, performance drops sharply. On APEX-Agents the best agent scored 24% Pass@1 at the January 2026 launch and 37.5% on corporate law as of a June 4, 2026 check.
- The headline number travels stripped of its caveats. Only 25 legal tasks are public, the scored 100 have no published composition, and the judge’s accuracy is unvalidated — most of which Mercor discloses, even if its citations don’t.
Corrections & Updates
- June 15, 2026: Strengthened the vendor-conflict disclosure to note the at-least-seven class-action data-breach suits filed against Mercor in April 2026, which bear on the provenance of the expert data underpinning the benchmark; added the “evaluation awareness” thesis — frontier models can recognize when they’re being tested, a benchmark-integrity problem that scales up with model capability — to the gaming preface and the Caveats section; and noted that the output-strong/autonomy-weak finding now matches mainstream legal-tech consensus.
The question a managing partner should be asking: if I hand this tool the same work I’d hand a third-year associate — an actual assignment that takes hours, requires reading source documents, and needs to meet specific quality criteria — what percentage of the work meets the standard?
The answer splits in two, and the split is the thesis of this post. Under structured conditions — a defined task with the documents in hand — today’s best models often clear the bar. Turned loose on an associate’s actual project, navigating a messy file environment from start to finish, they mostly don’t. APEX measures the first; its agent benchmark measures the second.
First, a caveat that applies to every benchmark number, not just APEX’s. AI benchmarks get gamed: labs optimize directly for the scores that make headlines, and a public test becomes a target the moment it ships (Goodhart’s law). Two mechanisms do most of the damage. The first is contamination — once a test set is on the open web it seeps into the next model’s training data, so a high score can measure memorization rather than reasoning, which is why serious benchmarks keep most of their questions hidden. The second is teaching to the test — fine-tuning a model on benchmark-style data can inflate the number with little general gain. A third is subtler: evaluation awareness, where a frontier model detects that it is being tested and adjusts its behavior — the benchmark as a defeat device, recognizing the rig the way a car’s emissions software once did. Contamination and teaching-to-the-test corrupt a score from outside; this corrupts it from inside.
Benchmarks aren’t neutral instruments, either. Whoever builds one has incentives: vendors publish benchmarks their products win, and a data company benefits from one showing that models fail without better data. So the first question about any score isn’t “how high” but “who measured it, on what, and what do they sell.” Three legal-AI benchmarks make the point, because each measures something different for a different reason. LegalBench (Stanford) is academic — 162 crowd-sourced reasoning tasks, exact-match scored, free and peer-reviewed; it asks whether a model can reason about law. legalbenchmarks.ai is a practitioner community that publishes independent evaluations of the legal-AI products firms actually buy. APEX, the subject of this post, comes from a data vendor and tests whether frontier models can produce hours-long professional work product. Three builders, three questions — which is exactly why, with any score, you start with who’s behind it.
A team at Mercor built APEX, and Mercor is not a neutral party — it sells the expert data that benchmarks like this one show models need.1 Still, it gets a lot right.
APEX Is the Right Kind of Benchmark#
The AI Productivity Index (APEX) tests whether frontier AI can do economically valuable professional work across four jobs: investment banking associate, management consultant, BigLaw associate, and primary care physician. It launched in September 2025 and was extended in December 2025; the technical report, evaluation harness, and a 100-task development set are all public.
What sets it apart is who built it and what it tests. Mercor — Scale AI for specialized professions — recruited 137 professionals averaging 7+ years, the law contributors drawn (in Mercor’s framing) from firms like Latham & Watkins, Skadden, and Cravath, advised by Cass Sunstein. Each wrote tasks from their actual day-to-day work — review a set of financial filings, identify the indemnification structure, draft a memo on whether the buyer’s exposure exceeds the cap — and a grading rubric of, on average, 14 binary pass/fail criteria, like unit tests for legal work product.
The scale is serious. The hidden evaluation set holds 400 tasks (100 per profession), each with real source documents — PDFs, spreadsheets, contracts, financial models, up to 100,000 tokens combined — that take a seasoned professional 2.7 hours on average. Models run eight times per task, with scores reported at 95% confidence. This is the deliverable a partner would expect on their desk, graded as the expert would grade an associate’s.
Measured against the traps in the preface, APEX does well. It limits contamination by keeping the 400 scored tasks private while publishing 100 development cases with their full prompts, sources, and rubrics; it ships an open harness, documents its model settings and judge prompt, and reports confidence intervals and significance tests. That is more transparency than most legal-AI benchmarks offer — and it is what makes the caveats later in this post possible at all, since they come from reading Mercor’s own appendix and harness, not from guesswork. One caveat on that openness: an open harness is not an open project. Surveying legal-AI’s open-source theatre, Houfu Ang shows corporate benchmarks publishing code while merging almost no outside contributions — the welcome mat without a community. APEX’s openness is the auditable kind, not the communal kind; it’s enough to check the work, which is all this post needs. The honest comparison is LegalBench, which scores short, atomic tasks by exact match against gold labels — objective and reproducible — where APEX grades hours-long deliverables with an LLM judge. APEX bought realism at the cost of grading rigor. That trade runs through everything below.
The Legal Result Is Impressive but Bounded#
In the December 2025 report (models tested that November), GPT-5 (Thinking=High) leads overall at 67.0%, followed by Gemini 3 Pro at 64.3% and Grok 4 at 63.5%. Law is the standout domain.

Law tops every profession by a wide margin — 77.9%, versus medicine’s 65.5% and consulting’s 64.0% — with three OpenAI models taking the top law spots and Claude Opus 4.5 (Thinking=On) at 74.0%. Those are the December figures; as checked June 4, 2026, the live Big Law leaderboard put GPT-5 (High) at 76.6%, with newer models close behind. The model order shuffles with each release; the domain pattern doesn’t — law has stayed the top profession in every snapshot since launch.
Read closely what “law” means here, though. The model is handed the source documents, the task is fully specified, and the output is judged against an itemized rubric. Under those structured-output conditions — answer supplied, question defined, criteria fixed — today’s models are genuinely strong at legal analysis and drafting. That is a real capability, and a bounded one. It tells you a model can answer a hard legal question with the materials in front of it. It says nothing yet about whether it can run the matter that produces the question.
APEX-Agents Shows the Missing Layer#
APEX-Agents (January 2026) measures the harder thing: whether an agent can complete a project — navigating files, using tools, and executing multi-step workflows in real software environments.
It’s built differently. Per the technical report, 256 experts — consultants from BCG and McKinsey and corporate lawyers at Disney and other Fortune 500 companies — built 33 project scenarios, each a simulated 5-to-10-day client engagement. Note the legal contributors: in-house corporate lawyers, not BigLaw firm associates — which shapes what “lawyer work” means here. The scenarios run inside Mercor’s own containerized sandbox (Archipelago), exposing nine applications (calendar, mail, documents, spreadsheets, code execution, and more). Each world averages 166 files; the 480 tasks (160 corporate-law, across 12 legal “worlds”) require agents to find the right files, reason across them, and produce a deliverable in about 1.8 hours of expert-estimated work.

The metric is Pass@1 — does the agent get it right on the first try? In the report’s January 2026 results, Gemini 3 Flash (Thinking=High) led at 24.0% overall and 25.9% on law; GPT-5.2 followed at 23.0%, with Claude Opus 4.5 and Gemini 3 Pro at 18.4%.
Open-source models scored below 5%.
The agents leaderboard, which Mercor updates outside the technical report, has improved fast — and every figure needs a timestamp and a harness label. As checked June 4, 2026, the overall board was led by Gemini 3.5 Flash at 49.6% Pass@1, with Claude Opus 4.8 topping corporate law at 37.5% — both on Mercor’s newer “Loop” harness. On the ReAct harness the January paper used, the best corporate-law score was 29.8%. The same models score ~8 points higher on law from better scaffolding alone — a reminder that when a vendor credits “the model,” the harness may be doing the work. And the domain order inverts the APEX story: law’s 37.5% sits well behind consulting (55.5%).
The inversion has causes APEX reports directly. Law tasks carry more all-or-nothing criteria than other domains (4.57 per task on average, all required for Pass@1) and are the longest in the benchmark (2.4 hours). Generic agentic gains — file navigation, tool use, computation — convert straight into completed tasks when the output is a machine-checkable number. Law’s bottleneck sits after the navigation: a judgment-graded deliverable that better tool use alone doesn’t finish.
The report’s failure analysis is more concrete than the vendor narrative. Across all eight agents, at least 40% of runs score zero — though part of that is the benchmark’s design: 92 of 480 tasks have a single criterion and 79 have two, and Pass@1 requires meeting every one, so one miss zeroes the task. Open-source agents fail differently — Kimi K2 Thinking times out on 29.8% of tasks by exceeding the 250-step cap (“doom-looping”), versus under 4% for the best closed agents. Agents can often produce partial output — mean scores and Pass@8 run ~15 points above Pass@1 — but rarely complete a task correctly on every attempt, with Pass^8 dropping 10–12 points below Pass@1. The capability is real; the consistency isn’t.
One more data point cuts both ways. Applied Compute used reinforcement learning on Mercor’s expert-labeled data to post-train a model for these tasks; on corporate law, Pass@1 tripled from 4.4% to 16.3%. So the gap is partly a training-data problem, not purely a capability ceiling — but 16.3% is still a long way from reliable, and the finding comes from the company that sells the data.
That Divergence Is the Point#
Put the two benchmarks together and the shape is unmistakable. The same legal work that scores highest when a model answers a defined question scores lowest when an agent has to execute a project. Law is the easiest profession for a model to answer and the hardest for an agent to do.
The exact percentages should not be read as deployment thresholds. The pattern matters more than the point estimates: legal output generation is much further along than legal workflow autonomy. Models are becoming good at legal work product — drafts, analyses, extractions, issue-spotting against a known frame. They are not yet dependable legal workers — navigating a data room, holding a plan across dependent steps, and producing sound work product on the first try.
For a firm, the line that matters is about the kind of work, not a score. Lean on AI for bounded output generation with a human reviewing it; keep humans on open-ended, multi-step matters. This is the mainstream legal-tech read, not a contrarian one. As Troutman Pepper Locke’s Will Gaus told Law.com, responsible deployment requires “control points built into workflows so there is the ability to intervene, validate and correct” — the firms that get it right “treat agentic AI as a controlled extension of their existing processes, not as an autonomous layer operating alongside them.” The vendors selling agentic AI for legal work — Harvey’s 700,000 daily agentic tasks, CoCounsel’s autonomous workflows, Anthropic’s Claude for Legal plugins — ship real products doing real work, but APEX-Agents says the best agent still fails most realistic corporate-law tasks. So each output arrives with no signal about whether it’s right, and a lawyer must check it as if it were wrong. That verification, not the API bill, is where the cost lives.
The Caveats#
These matter, but they’re secondary to the divergence above — and most are limitations Mercor discloses rather than hides.
The 77.9% rests on 100 held-out legal tasks Mercor keeps hidden — necessary, since a test only stays valid if models can’t train on it. What’s public is 25 legal cases the report explicitly labels “non-benchmark example cases.” Mercor doesn’t claim they represent the hidden 100, and no outsider can confirm they do. Going through them, most aren’t BigLaw work: the bulk are criminal matters, personal-injury and tort problems, Social Security disability appeals, and probate disputes — the staples of a general practice or a bar exam. Only a handful are the transactional, corporate, or regulatory tasks a BigLaw associate actually bills. And a domain score is only as meaningful as the task mix behind it: APEX publishes no composition for the scored set — no breakdown by practice area, task type, or difficulty — so “law: 77.9%” could describe a model acing a hundred issue-spotters or clearing a hundred M&A diligence memos, two very different claims that collapse into one number. That gap is the subject of the next post in this series.
The grading is inspectable, and its limits are mostly disclosed. The score is an unweighted mean of binary criteria, graded by a single mid-tier judge (Gemini 2.5 Flash) that sees only the criterion and the model’s answer — not the source documents or the rubric’s cited authority — by design, on the rationale that each criterion is “objective, specific, and self-contained.” That holds for extraction (“states the jurisdiction is Florida”); it is shakier for the reasoning criteria that drive the law score, where judging correctness requires the controlling authority the rubric stores but doesn’t hand the judge. The one limitation Mercor asserts rather than discloses is the judge’s own accuracy: the report says the judge “maintains high performance” but, unlike the APEX-Agents paper (a confusion matrix, 98.5% against human labels), publishes no human-agreement check for the legal tasks. A 77.9% is only as good as the grader behind it, and that grader’s accuracy never appears in print.
The last caveat is about the models APEX grades, not APEX itself: evaluation awareness.
Frontier models can increasingly tell when they’re being tested — Anthropic’s Claude Sonnet 4.5, in its own system-card testing, flagged that it was likely under evaluation in over 80% of one safety battery — and the ability scales up with model size, so the newest, highest-scoring models are the ones best at recognizing the exam. Most of that research covers safety evals, where a model has an obvious motive to look aligned; a capability test like APEX gives it less reason to throw a drafting task, so the risk is smaller than the sandbagging headlines imply. But APEX’s structured law format — filing supplied, rubric-shaped question posed — is close to the platonic shape of a test. For the managing partner this post opened with, that reframes the procurement question: not “what did it score on the benchmark” but “how does it perform on my matters, where nothing signals a grader is watching” — a figure no public leaderboard, APEX included, can supply. One more reason to read the 77.9% as a ceiling under ideal conditions, not a floor you can count on in the file room.
None of this is a gotcha — Mercor discloses nearly all of it. The failure is downstream, where “77.9% on BigLaw tasks” gets cited — by vendors, by the press, by a partner building the case for a tool — with every one of these caveats stripped off. Re-attaching them is what this series is for. Next, I’ll run the open harness on all 25 public legal tasks, across several frontier models, with a second grader, to see how much the choice of judge moves the score.
Further Reading#
Primary sources and independent benchmarks:
- The AI Productivity Index: APEX-v1-extended. Vidgen et al. The APEX technical report.
- APEX-Agents. Vidgen et al. The agentic benchmark technical report.
- APEX-v1-extended on Hugging Face. The open development set (100 tasks, 25 legal, CC-BY).
- LegalBench. The 162-task legal reasoning benchmark from Stanford/NeurIPS.
- Vals AI Legal Benchmarks. Independent model evaluations on LegalBench tasks.
- Lawyers Are Building. Just Not On Each Other’s Code. Houfu Ang (Alt + Counsel). On “open-source theatre” in corporate legal-AI benchmarks.
- Memo: Defeat Devices for Benchmarks. Signal Memo. On “evaluation awareness” — why frontier models’ ability to recognize a test undercuts the benchmark scores procurement relies on.
- Agentic Systems Add New Layer of AI Hallucination Risk in Legal Work. Troutman Pepper Locke (quoting Law.com). The mainstream legal-tech case for human control points over autonomous agents.
- AI Startup Mercor Faces Lawsuit Over Data Breach. PYMNTS. On the April 2026 class-action suits over Mercor’s handling of contractor data — relevant to weighing the benchmark builder’s incentives.
Mercor and vendor materials (read with the seller’s commercial interest in mind):
- APEX Leaderboard. Mercor’s live results across tested models.
- APEX-Agents Leaderboard. Mercor’s live agentic results, updated outside the technical report.
- Building State-of-the-Art Agents with Mercor. Applied Compute’s post-training case study (a Mercor data partner).
- BigLaw Bench. Harvey’s vendor-built legal benchmark.
This post is part of The Benchmarks series on LegalRealist AI. It is intended for informational and educational purposes only and does not constitute legal advice. AI capabilities, benchmark results, and model performance described here reflect publicly available information as of the publication date and are subject to rapid change. APEX technical-report figures reflect models tested in November 2025; APEX-Agents launch figures reflect January 2026. Live leaderboard figures are as of June 4, 2026. Current model versions may perform differently. Laws and ethics rules governing AI use in legal practice vary by jurisdiction.
A disclosure worth weighing: Mercor’s core business is selling expert-generated training data to AI labs — a reported $500 million revenue run rate and $10 billion valuation as of late 2025. A benchmark showing that agents fail at professional work, paired with a case study showing that training on Mercor’s data fixes it, aligns neatly with that commercial interest. The methodology is open and auditable; the “it’s a data problem” framing is also the sales pitch. The task authors are also anonymous contractors, so the “firms like Latham” framing can’t be checked against named individuals. And the conflict runs deeper than commercial incentive. In April 2026 Mercor was served with at least seven class-action suits over a data breach that allegedly exposed contractor job-interview recordings, facial biometric data, and screenshots of workers’ computers; one suit alleges the company trained client models on materials potentially owned by other companies (PYMNTS, reporting on a Wall Street Journal story; Mercor “strongly dispute[s] the speculative claims”). A benchmark’s authority rests on the integrity of the expert data behind it; active litigation over how Mercor collects and uses that data is a material discount on that authority, not a side issue. ↩︎