TL;DR
- The Kaggle dataset taught the field to frame Medicare fraud detection — on data nothing like the real thing. 5,012 providers, pre-labeled fraud flags, heavily enriched classes. Dozens of repos and papers built on it. None proves prospective detection on raw CMS releases.
- The most useful public repos use real CMS data — and outline a backtest pipeline I did not find in public form. One does clustering on raw provider billing with a browsable dashboard. Another cross-references against the OIG exclusion list. Chaining them together with historical data could produce labeled enforcement proxies. The data exists. I did not find a public repo that connects it end-to-end.
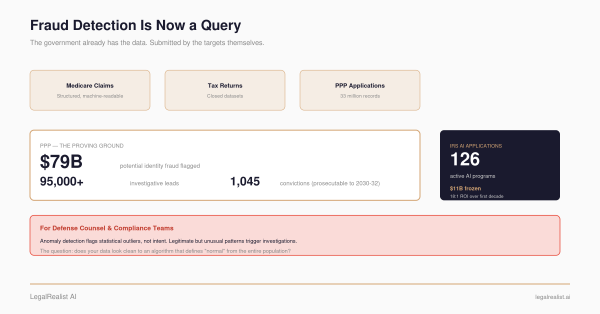
- The PPP dataset is the benchmark CMS should be measured against. SBA released identified borrowers, lender names, employee counts — and the fraud typologies were self-evident from the data itself. CMS releases provider-level aggregates with programs siloed and typologies buried in press releases.
- An MCP server makes CMS data queryable by LLMs — same data, easier interface. Once configured, an analyst can ask the outlier question in plain English instead of opening a notebook. The interface changes. The data underneath does not.
- Five releases would bring CMS data closer to the PPP benchmark. Cross-program provider linkage, longitudinal trends, outcome data, structured fraud typologies, and coding reference tables. All provider-level, with privacy and gaming risks still needing guardrails. The bottleneck isn’t code — it’s what CMS decides to publish.
Update, June 24, 2026: This post was tightened to describe small open-source repositories as proof-of-concept examples rather than mature systems; to correct the OIG exclusion-code discussion; to treat LEIE as an enforcement proxy rather than a clean fraud label; and to distinguish Medicare fraud estimates from broader health-care-fraud estimates.
The PPP fraud analysis worked because the SBA released unusually inspectable data — 11.5 million loans, identified borrowers, identified lenders, and enough application fields to make anomalies visible. An open-source pipeline flagged 1.19 million suspicious loans, and several high-overrepresentation lenders overlapped with congressional scrutiny, DOJ enforcement history, or other public warning signs. Medicare spends roughly $1 trillion annually — more than four times what PPP disbursed over its entire lifetime. The public data available for outside analysis is worse by an order of magnitude.
The Kaggle Foundation#
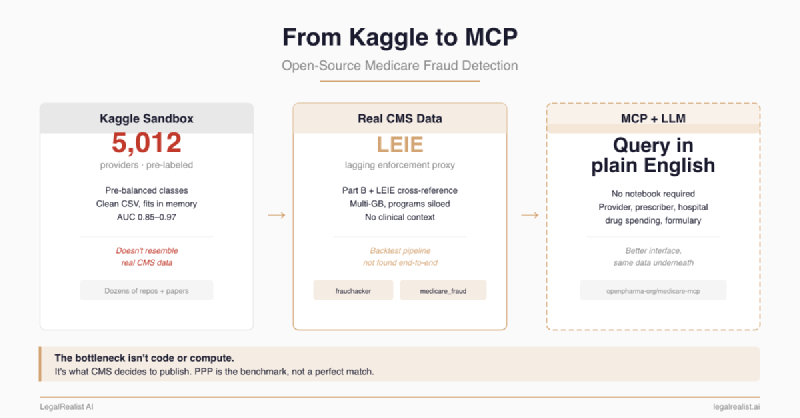
Most open-source Medicare fraud detection traces back to one dataset: Rohit Anand Gupta’s Healthcare Provider Fraud Detection Analysis, posted to Kaggle in May 2019. It contains 5,012 providers, roughly 558,000 claims, beneficiary demographics, inpatient and outpatient splits, diagnosis and procedure codes, and — crucially — pre-labeled fraud flags at the provider level. It has spawned dozens of GitHub repositories, Kaggle notebooks, Medium writeups, a March 2026 medRxiv preprint, a Journal of Big Data paper (2023), and an IEEE conference paper.
The repos follow a consistent pattern: feature engineering on claim amounts, chronic condition counts, and provider geography, then classification via logistic regression, random forest, XGBoost, or autoencoders, producing AUC scores in the 0.85–0.97 range. SMOTE handles class rebalancing. SHAP values provide explainability. The machine learning works. The dataset doesn’t resemble reality.
The Kaggle set is heavily enriched relative to actual Medicare fraud rates, pre-processed into clean features, and small enough to fit in memory on a laptop. Models trained on it produce impressive accuracy numbers that do not prove prospective detection on real CMS releases — where the enforcement-positive rate is orders of magnitude lower, the features are aggregated and de-identified, and the clinical context that distinguishes fraud from unusual-but-legitimate practice doesn’t exist.
The Pyligent CMS-Medicare-Data-FRAUD-Detection repo (23 stars, 22 forks as of June 2026, last pushed in 2019) sits between the Kaggle sandbox and real detection. It uses actual CMS Part D prescriber data — over 3GB — processed through Apache Spark and PySpark, joined with LEIE exclusion data and pharmaceutical payment records. More ambitious data handling, more realistic scale, but still a small proof-of-concept project doing supervised classification against known exclusions.
The Bridge: Real CMS Data#
Two small repos cross the line from Kaggle toy to actual CMS data — and together they outline a pipeline I did not find in public end-to-end form.
dchannah/fraudhacker (18 stars, 8 forks as of June 2026, last pushed in 2017) is the most complete tool architecturally. It loads raw CMS provider utilization data into PostgreSQL, runs clustering-based outlier detection per specialty per state, and serves results through a Flask dashboard a non-coder can browse. The approach is more honest than supervised classification: it says “this provider bills differently from peers” rather than “this provider resembles previously caught fraudsters.” But fraudhacker never checks whether its outliers actually turned out to be fraudulent. No LEIE cross-reference, no validation against later enforcement, no feedback loop. It flags statistical anomalies and stops.
brenfrrs/medicare_fraud (4 stars, 6 forks as of June 2026) does what fraudhacker doesn’t: it joins Part D prescriber data against the OIG’s List of Excluded Individuals and Entities (LEIE) using NPI numbers. LEIE is the closest public enforcement proxy, but it is not a clean fraud label: exclusions can follow fraud convictions, license revocations, patient abuse or neglect, controlled-substance offenses, unnecessary or substandard services, false claims, kickbacks, loan defaults, and other administrative grounds. The repo’s models found gender, total claim count, and 30-day fill counts as the strongest predictors of exclusion — which immediately raises the question every honest fraud analyst has to ask: are those fraud signals, or demographic and volume correlates that happen to overlap with the providers OIG already caught?
Both repos use the same freely downloadable CMS public datasets. Both hit the same wall: the LEIE is a binary, lagging enforcement proxy. A provider appears on the list only after investigation, prosecution or administrative action, and formal exclusion. The label says who got excluded. It doesn’t necessarily say how the fraud worked, whether the exclusion involved fraud at all, or what the billing looked like before exclusion.
The Public Backtest I Did Not Find#
The data to go further already exists. The LEIE includes exclusion dates and exclusion type codes under Sections 1128(a) and 1128(b) of the Social Security Act — structured categories, not prose. 1128(a)(1) is conviction for program-related crimes. 1128(b)(6) covers excessive charges, unnecessary services, or services that fail to meet professionally recognized standards. 1128(b)(7) covers fraud, kickbacks, and other prohibited activities. Those categories are still legal categories, not billing signatures, but they are more structured than press-release prose. CMS publishes Part B provider utilization data going back to 2013. The NPI is the join key.
The pipeline: pull the LEIE with exclusion dates and type codes, pull the historical CMS billing data for excluded providers in the two to three years before exclusion, reconstruct their billing trajectories — what changed, what spiked, what deviated from specialty peers — and cluster those trajectories by exclusion category. The output would not be clean proof of fraud. It would be a set of enforcement-linked billing signatures: this is what later-excluded cardiology billing looked like in Florida before exclusion. This is what later-excluded DME supplier billing looked like in Texas. Then run those signatures against current provider data to find active providers whose billing trajectories match.
Fraudhacker does the clustering but skips the validation. brenfrrs does the LEIE join but only as a static label on current-year data — not as a temporal backtest. I did not find a public repo chaining them together. It’s not a weekend project — it requires joining across multiple years of multi-gigabyte CMS datasets and aligning temporal windows correctly — but it’s not research-level hard either. It’s the kind of analysis the Dicklesworthstone PPP pipeline approximated for loans.
The backtest is buildable with today’s public data. But “buildable” and “practical” aren’t the same thing. CMS publishes each year’s data as a separate file in a slightly different format. The LEIE’s exclusion type codes map to legal categories, not billing patterns — translating “conviction for program-related fraud” into “which CPT codes spiked” requires the feature engineering CMS could provide but doesn’t. And the analysis would still run on provider-level aggregates with patients de-identified and programs siloed. Better data from CMS wouldn’t just help — it would determine whether the backtest produces actionable fraud signatures or statistical noise.
The PPP Benchmark#
The PPP contrast shows what better data looks like.
The SBA FOIA dataset gave outside analysts identified borrowers (business name, address), identified lenders, exact loan amounts, self-reported employee counts, NAICS codes, approval dates, and forgiveness amounts — 11.5 million loans in a single 8.4GB CSV. The fraud typologies were self-evident from the data: a business claiming ten employees with zero payroll on tax records is the scheme. A lender approving thousands of loans with identical metadata is the red flag. No external translation required. An open-source pipeline built on this data flagged 1.19 million suspicious loans, and several high-overrepresentation lenders overlapped with enforcement history, congressional scrutiny, or other public risk signals.
CMS gives outside analysts something fundamentally different. Provider-level billing aggregates — not claim-level records. Patient identifiers removed. Part B billing, Part D prescribing, DMEPOS orders, and Open Payments pharmaceutical income released as separate datasets on different schedules in different formats. They’re joinable on NPI, but the joins are non-trivial and the temporal alignment between datasets is inconsistent.
Medicare fraud typologies require a clinical translation layer the public data doesn’t provide. “Upcoding” means billing a higher-complexity office visit code than the encounter warranted — but the encounter notes aren’t in the public data. “Unbundling” means billing lab tests separately instead of as a panel — detectable if you know which CPT codes should be bundled, but CMS doesn’t publish the bundling rules alongside the billing data. “Phantom billing” — services billed but not rendered — should show up as high volume with low unique beneficiaries, but that pattern also describes a legitimate high-throughput specialist.
The biggest gap isn’t any single missing field. PPP was one self-incriminating table — the fraud signals were in the application. Medicare is five tables that CMS treats as unrelated releases, and the information that would connect billing anomalies to fraud patterns is stripped or siloed.
The MCP Frontier#
The tooling is getting better even as the data stays the same. openpharma-org/medicare-mcp is a new, unofficial, lightly starred proof-of-concept server that wraps CMS data into Model Context Protocol (MCP) tool calls — including search_providers (Part B, 2013–2023), search_prescribers (Part D by drug, NPI, specialty, and state), search_hospitals (inpatient utilization and payment), search_spending (drug spending trends), search_formulary (Part D plan coverage), plus hospital quality metrics including star ratings, readmission rates, and mortality.
Once configured, this can drop the barrier from “can you write Python and handle multi-gigabyte CMS data formats” to “can you ask the right question and interpret the answer.” A compliance analyst connected to this MCP server through Claude Cowork or another LLM-based tool could ask “which cardiologists in South Florida billed Medicare for more than 3x the state average for stress tests last year” and get a structured answer without opening a Jupyter notebook. A qui tam relator screening for potential leads could run the same kind of outlier identification the Python repos do — specialty-level billing comparisons, geographic clustering, provider-level Anomaly Detection — through conversation. That is a useful interface change, not a validation layer.
The MCP server fits into a broader pattern: DeepJudge built an MCP connector for searching a firm’s prior matters. Midpage connected legal research tools for citation verification. Domain-specific datasets are becoming LLM tools. For healthcare fraud, the dataset is there. But the LLM queries the same de-identified, aggregated, program-siloed data underneath. A better interface to limited data is still limited analysis.
Closing the Gap#
The backtest pipeline described above is buildable on today’s public data, but every step is harder than it needs to be. The PPP dataset is a useful benchmark for what CMS could release. Five changes would narrow the gap.
Cross-program provider linkage. A provider’s Part B billing, Part D prescribing, DMEPOS orders, and Open Payments income currently arrive as separate datasets. A unified provider profile — one record per NPI per year linking all four programs — is what DOJ builds internally when it constructs a fraud case. The join key exists. CMS just doesn’t do the join publicly. All provider-level, no patient exposure.
Longitudinal billing trends. The current releases are annual snapshots. A provider whose billing doubles year-over-year, whose specialty mix shifts suddenly, or whose patient panel changes dramatically doesn’t show that trajectory in a single year’s file. Multi-year trend data at the provider level would add the temporal dimension that made PPP Anomaly Detection work — the Dicklesworthstone pipeline flagged lenders partly because their approval volumes spiked in ways that didn’t match normal lending behavior over time.
Provider-level outcome data. CMS already publishes hospital-level quality metrics — star ratings, readmission rates, mortality. Carefully risk-adjusted, aggregate outcome data at the provider level could help outside analysts distinguish high-billing providers whose patients do well (legitimate high-acuity practice) from high-billing providers whose patients fare worse (potential overtreatment, fraud, or low-quality care). This would need small-cell suppression, risk adjustment, and reidentification safeguards. Billing volume alone can’t make that distinction. Billing volume paired with outcomes might.
Structured fraud typologies. This is the biggest gap between PPP and Medicare — and the one the backtest pipeline would most benefit from. PPP fraud typologies were self-evident from the data. Medicare fraud typologies require clinical translation. DOJ press releases describe schemes in prose. There’s no structured dataset mapping those descriptions to billing signatures.
For each LEIE exclusion — or at least a redacted, representative sample — CMS could publish the fraud typology (structured categories, not narrative), the billing signature (which CPT codes, what volume patterns, what geographic and temporal markers), and the pre-exclusion billing trajectory from the provider utilization data. A dataset that says “this is what upcoding looked like in Part B claims — here are 50 confirmed examples with their billing patterns before exclusion.” That would turn the backtest from a feasible-but-painful exercise into a more practical detection tool. It would also need guardrails: typology releases can expose investigative methods and teach bad actors how to evade obvious screens. DOJ’s FOCUS initiative tells data miners to bring more sophisticated analysis. Redacted typology data would give them something to apply that sophistication to.
Coding and bundling reference data. CMS knows which CPT codes should be billed together, which modifier combinations are legitimate, and what normal utilization ranges look like by specialty and geography. Publishing that reference data alongside the billing data would let outside analysts flag unbundling and upcoding against a known standard — the way the PPP pipeline flagged impossible NAICS-employee combinations against business registration norms — instead of relying on statistical deviation from peer averages.
All five proposals expose provider behavior, not patient identity. Open Payments already publishes provider-identified pharmaceutical industry payment data — full names, searchable, downloadable — under the Physician Payments Sunshine Act. The precedent for provider-level transparency exists.
The data for a Medicare fraud detection pipeline already exists — historical billing, exclusion proxies with dates and type codes, NPI linkage across programs. An outside analyst can build a rough backtest today. But each step requires joining datasets CMS treats as unrelated, aligning temporal windows across files published on different schedules, and translating legal exclusion categories into billing features without reference data. The five proposals above wouldn’t just make new analysis possible — they’d make the analysis that’s already possible practical. The PPP experience showed what happens when the friction drops: outside analysts can surface patterns that overlap with later enforcement signals, including in the long tail where DOJ doesn’t have resources to look. Health-care fraud is often estimated at 3–10% of total health spending, which NHCAA describes as tens of billions of dollars annually and potentially more than $300 billion across the entire U.S. health-care system. Applied to Medicare alone, the order of magnitude is still tens of billions, not a clean $100–350 billion Medicare-specific estimate. The data to surface more of it already exists. It’s sitting inside CMS.
Further Reading#
- Healthcare Provider Fraud Detection Analysis. The Kaggle dataset that launched the field.
- dchannah/fraudhacker. Clustering-based anomaly detection on real CMS data with a Flask dashboard.
- brenfrrs/medicare_fraud. Part D prescriber fraud detection using LEIE cross-referencing.
- Pyligent/CMS-Medicare-Data-FRAUD-Detection. PySpark-based analysis of CMS Part D data at scale.
- openpharma-org/medicare-mcp. MCP server making CMS data queryable by LLMs.
- OIG Exclusion Authorities. The statutory basis for LEIE exclusion type codes.
- Explainable Machine Learning Models for Medicare Fraud Detection. Journal of Big Data, 2023.
- CMS Open Payments. Provider-identified pharmaceutical payment data — the precedent for provider-level transparency.
- The Government Already Has the Data. How DOJ, CMS, and IRS use their closed datasets internally.
- The Data Miner’s Dilemma. The information asymmetry between public data and what DOJ holds, and why FOCUS doesn’t close it.
- Show Your Work. The open-source PPP fraud analysis pipeline and what it found.
This post is part of the Data Analytics and Fraud series on LegalRealist AI. It is intended for informational and educational purposes only and does not constitute legal advice. The data access proposals discussed here are the author’s analysis — not policy recommendations. Open-source repositories referenced are third-party projects not affiliated with LegalRealist AI. AI capabilities, data availability, and enforcement practices described here reflect publicly available information as of the publication date and are subject to change. Laws governing healthcare fraud, data privacy, and qui tam litigation vary by jurisdiction.