TL;DR
- Public data can produce enforcement-relevant anomaly maps. An open-source fraud-scoring system, run against the SBA PPP dataset, surfaced lender and geographic concentrations that overlap with known enforcement patterns — using public data, not subpoena power.
- Several high-overrepresentation lenders overlap with known enforcement targets. Harvest, Capital Plus, Benworth, Cross River, and Kabbage appear in the scoring output and in PPP enforcement history. That is a calibration signal, not proof that every high-overrepresentation lender was fraudulent.
- The geographic clusters match prosecution geography. South suburban Cook County, metro Atlanta, and South Florida — the three regions where DOJ has concentrated PPP enforcement — are the same three regions the scoring system flags at 3.2–4.4x overrepresentation.
- The system identifies where enforcement-relevant anomalies cluster. The application file proves the case. In every prosecution I checked, the public data pointed toward the right neighborhood, lender, or loan population. What converted the lead into a case was the SBA’s internal data — certifications, payroll records, bank activity — which is not in the public dataset.
- DOJ found the big cases. The small ones need better data. Kabbage and Robertson are cases DOJ builds with internal resources. The $20K fictitious sole proprietorship is the case DOJ often cannot justify staffing. This system is a strong example of public-input analysis — and it shows that the bottleneck is data, not just skill.
Corrections & Updates
- June 24, 2026: Narrowed the claim from “public data can source prosecutions” to “public data can produce enforcement-relevant anomaly maps.” The post now distinguishes heuristic flagging from fraud validation, clarifies that the XGBoost analysis tests separability from the system’s own labels rather than proven fraud, and adds caveats around repository audit, compute requirements, lender-volume confounding, and SBA OIG fraud estimates.
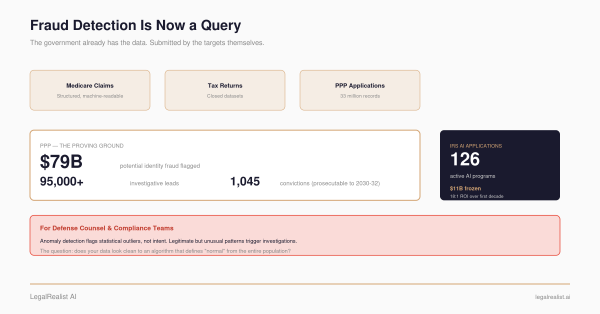
DOJ’s Pandemic Analytics Center of Excellence (PACE) cross-referenced 33 million PPP and EIDL applications against Social Security, HUD, and IRS records to source fraud cases. Its prosecutors have since brought hundreds of PPP prosecutions. An open-source scoring system, running on the SBA’s public FOIA data, surfaces some of the same lender and geographic concentrations that appear in enforcement history. Public data can identify suspicious clusters. The question is what happens with them — and whether the government will give data miners enough non-public context to move from anomaly to evidence.
The Scoring System#
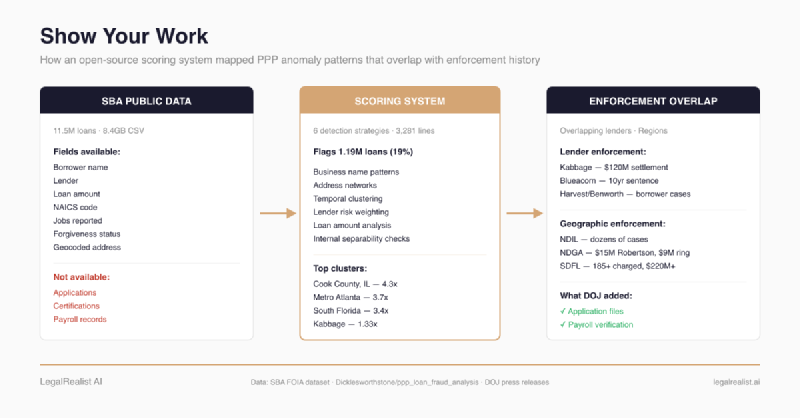
The Dicklesworthstone PPP fraud analysis is an open-source, three-stage scoring system built by Jeff Emanuel — a former hedge fund analyst turned developer whose broader open-source portfolio has 21,000+ GitHub stars across 170+ projects — to process the full 8.4GB SBA FOIA dataset: 11.5 million loans, every field structured and machine-readable. This specific PPP repository is lightly starred and should not be treated as widely audited; its value is that the code, data source, thresholds, and pre-computed output are inspectable. It’s not the only open-source PPP analysis — the Washington Post’s investigative team cross-referenced SBA data against SEC filings to identify public companies that took loans meant for small businesses, a different approach to the same underlying thesis. But the Dicklesworthstone system is an unusually complete public fraud-scoring effort: 3,281 lines of Python, pre-computed output publicly available, reproducible by cloning the repo and running it on a commodity workstation. It flagged 1.19 million loans out of 6.27 million in the $5K–$22K range as suspicious — an 18.99% flag rate. That is high, but it is not absurd in context: the SBA OIG has estimated at least $200 billion in potential fraud across PPP and EIDL, while SBA has disputed parts of that estimate. The comparison is not a clean base rate for small PPP sole-proprietor loans. It is only a scale check: a 19% anomaly rate in a self-certified, small-dollar segment is plausible enough to investigate, not low enough to treat as proof. The flags are based on a weighted composite of six detection strategies:
Business name analysis. Over 100 regex patterns match against borrower names, each assigned a suspicion weight. Names referencing luxury brands, fictional places (“Wakanda”), or get-rich-quick phrases (“Quick Cash,” “Free Money”) score near the maximum. More subtle signals include unusually short names (suspicious loans average 1.8 words vs. 2.5 overall, confirmed by Mann-Whitney U test at p < 0.01), multiple spaces suggesting copy-paste errors, and generic structures that don’t match how legitimate businesses typically name themselves.
Address network mapping. The system builds address-to-business graphs. When multiple “businesses” share a single residential address — say, four sole proprietorships at Apt 4B — each loan gets 15 risk points per overlap plus 5 per connected business.
Temporal clustering. The system tracks loan volumes by ZIP code and SBA office per day. If a ZIP code that averages 8 loans per day suddenly spikes to 50 on a single date, each loan from that spike gets a logarithmic risk boost. Sequential or near-sequential loan numbers — the last five digits differing by fewer than 20 — add 25 points, catching batch submissions from loan agents processing fabricated applications in rapid succession.
Lender risk weighting. A dictionary maps lenders to risk weights based on known enforcement history. Kabbage, for instance, is assigned a 0.8 weight — the system adds 12 risk points (15 × 0.8) to any Kabbage-originated loan that also carries other flags. The weighting is conservative: lender risk alone doesn’t trigger a flag. It amplifies existing signals.
Loan amount and demographic patterns. Loans hitting exactly $20,832 or $20,833 — the PPP maximum for a single employee — get 25 points. Suspicious loans cluster at $19K mean vs. $17K overall. Blank demographic fields compound with other flags.
Each loan gets a composite risk score. The system uses a threshold of 100 to flag, then a cutoff of 140 to sort the highest-risk loans for detailed analysis. The system minimizes false positives through known-business verification, contextual checks, and multi-factor requirements — a loan needs several independent risk signals to clear the threshold. Certain flag combinations use multiplicative interaction rather than additive stacking.
The engineering underneath is serious. The 8.4GB dataset is processed in chunks, and the published run is reproducible, but not trivial: the repository’s own README describes a multi-hour run on a 32-core, 128GB machine. Statistical tests support the descriptive differences between flagged and unflagged loans: Mann-Whitney U on business name length (p < 0.01), chi-square on demographic patterns (p < 0.001), t-tests on loan amount distributions (p < 0.05). A secondary XGBoost analysis tests whether the flagged population is statistically separable from the unflagged population on other features. That is useful, but it is not fraud validation: the model is learning against the system’s own heuristic labels, not adjudicated fraud outcomes, and the included output reports an error in the SHAP interaction analysis. The strongest claim is that the code, parameters, thresholds, and output are public enough to audit.
A scope caveat: the system analyzes only small-dollar loans, predominantly sole proprietors and self-employed filers. This is the population most vulnerable to fraud (applications were largely self-certified) but also the population most likely to include legitimate filers caught by heuristics not designed for them. “Suspicious” here means “statistically anomalous on multiple risk dimensions.” It does not mean “fraudulent.”
I didn’t build, modify, or run this system. I’m examining whether the risk concentrations it surfaces — using only the public CSV — correspond to the patterns that federal investigators acted on with subpoena power and non-public agency data. The Government Already Has the Data described what the government has; The Data Miner’s Dilemma described what outsiders don’t. The output puts numbers on that gap.
The Overlay#
Lenders#
Several overrepresented lenders — those appearing in the suspicious loan dataset far more often than in the general population — also appear in PPP enforcement history or in the fintech-partner ecosystem around prosecuted cases:
| Rank | Lender | Overrep. | DOJ Enforcement |
|---|---|---|---|
| #1 | Harvest Small Business Finance | 2.81x | Named as originator in multiple borrower fraud prosecutions; served as lender for Womply-routed applications |
| #2 | BSD Capital d/b/a Lendistry | 2.79x | High-volume small-loan lender; included here to show the table is not cherry-picking only enforcement matches |
| #3 | Capital Plus Financial | 2.46x | Lender for Blueacorn-routed loans; both Blueacorn co-founders prosecuted — Reis sentenced to 10 years/$66M restitution, Hockridge convicted of conspiracy |
| #4 | Fountainhead SBF | 2.40x | High-volume small-loan lender; another example where overrepresentation does not itself establish enforcement misconduct |
| #5 | Prestamos CDFI | 2.26x | Lender for Womply-routed applications; 8,839 unforgiven Texas loans totaling $143M |
| #6 | Benworth Capital | 2.22x | Named as originator across multiple fraud ring indictments in Brooklyn and Oklahoma federal court |
| #8 | Cross River Bank | 1.99x | Bank partner for fintech lenders including Blueacorn; processed billions in PPP loans |
| #13 | Kabbage | 1.33x | $120M DOJ settlement — inflated loans, removed underwriting steps, submitted thousands of fraudulent applications |
Source: Scoring output from Dicklesworthstone/ppp_loan_fraud_analysis. Enforcement outcomes from DOJ press releases and cited sources.
A caveat this table needs: these lenders appear at the top partly because they were large fintech-partnered PPP lenders by application volume. Harvest, Capital Plus, Lendistry, Fountainhead, and Prestamos collectively processed large numbers of small-dollar loans — the exact population the system scores. The overrepresentation may partly reflect “fintech-processed sole proprietor loans” rather than “fraud” per se. The lender overlay alone would be expected from volume and channel mix. Its value is narrower: as a calibration check, the scoring methodology produces outputs that overlap with known enforcement targets and known high-risk origination channels.
What DOJ found underneath: Blueacorn, the fintech routing applications through Capital Plus and other lenders, ran a “VIPPP” service that coached borrowers on submitting false applications and charged kickbacks based on a percentage of loan proceeds. Kabbage removed underwriting steps to maximize processing fees and discouraged fraud reviewers from requesting additional documentation. The scoring system sees the statistical shadow these failures cast across the dataset. DOJ proved the failures themselves.
Kabbage’s position at #13 rather than #1 illustrates a real distinction, though not one the system was designed to make. Kabbage’s fraud was institutional — inflating existing loan amounts, weakening controls — rather than volumetric, processing huge numbers of questionable applications through fintech passthrough arrangements. The heuristics respond to volume-based patterns, so per-loan manipulation registers differently.
Geography#
The geographic output is dominated by three regional clusters that also appear repeatedly in PPP enforcement coverage.
South suburban Cook County, Illinois: Harvey (4.28x overrepresentation, 1,933 flagged loans), Riverdale (4.33x, 1,554), Dolton (4.20x, 2,838), Calumet City (4.21x, 3,756), Bellwood (4.25x, 1,869), Maywood (4.21x, 2,160). Chicago proper at 3.78x with 98,244 flagged loans. DOJ has prosecuted dozens of cases here. In Dolton, federal prosecutors indicted police officer William Frederick Reed for fabricating payroll — Reed lived in Hazel Crest, also flagged at 4.06x. In Calumet Park (4.13x), the Illinois AG charged Raymond Harris, a Cook County Sheriff’s Office employee who fabricated a sole proprietorship to obtain $41,000.
Metro Atlanta, Georgia: Lithonia (3.70x, 6,452), Jonesboro (3.54x, 4,569), Riverdale GA (3.73x, 4,150), Decatur (3.35x, 7,234), Atlanta (3.29x, 34,417). Former assistant city attorney Shelitha Robertson was sentenced to over seven years for a $15M fraud scheme. The Northern District of Georgia separately charged ten individuals in a $9M ring.
South Florida: Opa-Locka (4.21x), Belle Glade (3.42x, 429), Lauderdale Lakes (3.29x, 1,592), Lauderhill (3.22x, 2,840). The Southern District of Florida hosts one of three national COVID-19 Fraud Strike Force teams and has charged over 185 people in PPP fraud schemes totaling $220M+. Miami-Dade, Broward, and Palm Beach counties received 4.2% of all PPP loans by count despite representing 1.8% of the national population — a disproportionate share that the scoring system independently identifies.

Three confounding factors apply to all three clusters. First, demographics: the system’s $5K–$22K range captures sole proprietor loans filed disproportionately in lower-income communities. Some overrepresentation may reflect who filed small-dollar PPP loans, not who committed fraud. Second, prosecution capacity: NDIL, NDGA, and SDFL are large, well-resourced U.S. Attorney’s offices. Third, fintech marketing: Blueacorn and Womply marketed aggressively in specific communities; geographic clusters may partly trace marketing reach. These factors may inflate the overrepresentation ratios. The right conclusion is not that the map proves fraud geography. It is that the map identifies anomaly concentrations that overlap with real enforcement activity.
From Lead to Case#
Reed (Dolton, IL): The system places his loan in a 4.20x geographic cluster. DOJ proved he fabricated his security company’s payroll, earned $189,000 as a police officer while claiming he needed a $5,862 PPP loan, and concealed the proceeds in a bankruptcy filing. The anomaly was visible in the public data. The proof was in the application file.
Harris (Calumet Park, IL): The system would place the loan in a 4.13x geographic cluster and might flag it for business-type or naming anomalies. The IL AG proved the business never existed, using the application itself and the absence of any state business registration. The anomaly was visible in the public data. The proof was in the state records.
Robertson (Atlanta, GA): The system sees metro Atlanta’s 3.29x overrepresentation. DOJ proved she submitted applications for companies she controlled, received $15M, and used the proceeds to buy a Rolls-Royce and jewelry. The regional anomaly was visible in the public data. The proof was in bank records and transaction tracing.
In each case, the public data pointed toward an anomaly associated with a real prosecution. What converted the anomaly into a case was the SBA’s internal data — borrower certifications, payroll records, bank activity. The government doesn’t only have better algorithms. It has better data. And it won’t share most of it.
The Cases DOJ Can’t Staff#
DOJ didn’t need this analysis to find Kabbage. A lender processing $7 billion in PPP loans with broken fraud controls surfaces itself. The $120M settlement, Robertson’s $15M scheme, the Blueacorn $65M conspiracy — DOJ builds these with PACE, cross-agency referrals, and multi-agency task force capacity. Big fish generate their own signal.
The question is below that threshold. The SBA referred 562,000 suspected fraudulent loans to Treasury for collection in April 2026 — $22.2 billion flagged but never previously investigated. Congress extended the statute of limitations to ten years. Enforcement runs through 2031. And DOJ has finite attorneys.
A $20,000 fabricated sole proprietorship in Calumet Park is hard for DOJ to originate on its own. The expected recovery may not justify the investigative cost. But it is exactly the kind of fact pattern data miners look for: low dollar amount, pattern-based identification, high volume. Harris’s $41,000 scheme was caught by the Illinois AG, not DOJ. The analysis flags populations where these cases may live. Multiply Harris by the thousands of statistically similar loans in the same geographic and lender clusters, and you are looking at the sort of long-tail enforcement problem DOJ cannot reach without better triage or outside help.
The Scoring System as Exhibit A#
DOJ’s False Claims Act materials recognize that many civil fraud investigations arise from qui tam actions. This scoring system is a strong example of what public-input analysis can produce — and the three prosecutions above show why the output is still only a lead map. The ceiling isn’t purely analytical. It’s informational.
This is the argument The Data Miner’s Dilemma made in theory. The scoring system makes it concrete. Data miners can build tools that identify risk concentrations similar to those that later appear in enforcement narratives. The PPP natural experiment showed that when the government releases better data — even involuntarily, via court-ordered FOIA — data miners can produce substantial enforcement outcomes. But public PPP data still bottoms out at “statistically anomalous.” If that is not sufficient, the question is not only whether data miners need better algorithms. It is whether they need better public signals.
What would better inputs look like? Not full application files — those contain sensitive personal information. But the SBA could release forgiveness status by lender, anonymized payroll-to-loan ratios, and cross-program flags showing whether the same borrower applied for both PPP and EIDL with inconsistent employee counts. None of this identifies individual borrowers. Cross-program flags are the strongest lever: if Harris claimed zero employees on his EIDL application and five on his PPP application, that inconsistency is in the government’s data right now. Releasing it anonymized wouldn’t expose Harris. It would expose the pattern — and the pattern is what moves data miners from “statistically anomalous” toward “inconsistent with the borrower’s own filings.”
The SBA already runs this analysis internally. The GAO found that SBA’s own analytics contributed to $4.7 billion in loan proceeds not being forgiven and 669,000 referrals to the OIG. The data exists. The analytical framework exists. The question is whether the government treats private enforcement capacity as a resource to be equipped or a nuisance to be managed. The system demonstrates that the analytical talent is there. The data isn’t.
Further Reading#
- Dicklesworthstone PPP Fraud Analysis Pipeline. The open-source scoring tool and pre-computed output used in this post.
- Washington Post PPP Loans Database. The Post’s investigative team cross-referenced PPP recipients against SEC filings to identify public companies that took small-business loans.
- SBA PPP FOIA Dataset. The full public PPP loan dataset.
- House Select Subcommittee Report on Fintech Fraud in PPP. Findings from 83,000 pages of subpoenaed lender documents.
- GAO: COVID Relief Fraud Schemes and Indicators. Analysis of 330 PPP and COVID-EIDL fraud cases and SBA data analytics capabilities.
- Kabbage $120M DOJ Settlement. Constantine Cannon’s analysis of the largest PPP lender settlement.
- SBA Refers 562,000 Suspected Fraudulent Loans to Treasury. April 2026 announcement on $22.2 billion in delinquent PPP and EIDL loans.
- PPP Fraud Enforcement Survey. Benesch’s overview of civil and criminal enforcement trends.
- Fraud and Abuse in the Paycheck Protection Program. Academic study cross-referencing PPP loans against SEC filings to estimate fraud rates in investment advisory firms.
- The Government Already Has the Data. Series post #1 on how DOJ, CMS, and IRS source fraud cases from structured data.
- The Data Miner’s Dilemma. Series post #2 on the gap between data miner analysis and DOJ’s evidentiary bar.
This post is part of the Data Analytics and Fraud series on LegalRealist AI. It is intended for informational and educational purposes only and does not constitute legal advice. The scoring system output discussed in this post is a statistical analysis of publicly available data — it does not identify fraud, and no individual, business, or lender discussed here should be presumed to have committed fraud based on statistical overrepresentation alone. Enforcement statistics, scoring output, and data availability described here reflect publicly available information as of the publication date and are subject to change. Laws governing fraud enforcement, the False Claims Act, and the public disclosure bar vary by jurisdiction and are evolving.