

TL;DR
- Harvey’s moat isn’t technology — it’s legal domain expertise and institutional plumbing. A former Latham associate reproduced the application interface in two weeks. What he couldn’t reproduce is the prompt engineering, DMS integrations, compliance certifications, and training data refined against millions of legal documents.
- Not all moats are equal — compliance and integrations erode; proprietary data doesn’t. SOC 2 certs and DMS connectors are engineering work. Westlaw’s editorially curated case law database and Harvey’s training data from millions of real legal documents are not.
- Enterprise pricing excludes most of the market by design. Harvey’s estimated $1,200–$2,000+ per seat per month with 20-seat minimums puts the annual floor above $288,000.
- The build-vs-buy calculation is firm-size dependent. At five attorneys, a Claude Team plan is the stack. At 500, SLAs and DMS integration make the vendor premium rational. The flip point sits around 30–80 attorneys.
- Dynamic competition — not any single tool — is reshaping the ecosystem. DeepSeek forced frontier model prices down. Mike forces transparency about what vendors sell. The competitive pressure cascades across layers, and the ecosystem reprices around what’s genuinely hard to replicate.
Corrections & Updates
- June 7, 2026: Corrected the Claude plan references and pricing. The five-attorney option is Claude Team ($25/seat/month, or $20 on annual billing; 5-seat minimum), not Claude Enterprise (which requires a 20-seat minimum and custom pricing). Team and the API include a DPA and a no-training-on-inputs commitment under Anthropic’s Commercial Terms; true zero data retention is a separate, API-only ZDR agreement, not a feature of any seat-based plan.
In late April 2026, a former Latham & Watkins associate named Will Chen posted a GitHub repo and a clean website. He called the project Mike — after Mike Ross from Suits, the unlicensed associate who can do unconventional work precisely because he isn’t bound by how things are supposed to be done. Harvey AI already took the senior partner’s name. Will took the other half of the metaphor.
The r/biglaw thread and Hacker News submission that followed generated admiration, skepticism, and a commenter noting that what legal professionals actually pay for — and what is virtually impossible to replicate — is access to a verified legal database of case law. Both reactions are right, and the tension between them tells you where legal AI is actually headed.
What Mike Reveals About Harvey’s Moat#
What Will built in two weeks is a web application with a chat interface, document upload, project management, and a retrieval pipeline. What Harvey has built over several years — and what justifies its reported $5 billion valuation — sits in the layers beneath the interface.
But not all moats are created equal. Mike’s existence forces a sorting exercise: which of Harvey’s advantages are durable, and which are speed bumps that open-source will pave over?
Moats That Erode#
Compliance and certification. SOC 2 and ISO 27001 are process certifications, not technology. Any firm with a competent IT team and a compliance budget can obtain them — they take months, not years. An open-source deployment shifts that burden to your firm, but the burden is administrative, not architectural. As managed legal AI infrastructure matures (the LAMP analogy below), compliance will get bundled into hosting services the way AWS handles it today.
DMS integrations. Harvey and Legora integrate with iManage, NetDocuments, Microsoft 365, billing software, and the collaboration platforms firms already use. These integrations are engineering work — significant, but not proprietary. Open-source projects routinely build connectors to enterprise systems. If Mike attracts enterprise contributors, these integrations will get built the same way MCP connectors are proliferating across the Claude ecosystem.
Production hardening. Will built Mike in two weeks using AI-assisted coding — what we described in The AI Use Spectrum as Level 3: ad hoc tools built fast, dangerous as permanent infrastructure. His public GitHub history prior to Mike consists of tutorial projects — a calculator app, a snake game, a forked React course — suggesting the platform was generated primarily by AI coding assistants rather than years of engineering experience. That reinforces the thesis: the Application Layer is so commoditized that someone without a professional engineering background can reproduce it. But it also means the code hasn’t been reviewed for security vulnerabilities that matter when client data is involved. No penetration tests, no SOC 2 audit, no data retention policies. This gap is real today and will close as the project matures — Linux, LangChain, and LlamaIndex all started the same way.
Moats That Hold#
Proprietary legal data. Harvey has a custom case law model built on proprietary training data and evaluation sets refined against millions of real legal documents. This isn’t Prompt Engineering that a clever developer can replicate — it’s the accumulated judgment of lawyers who’ve reviewed thousands of outputs and corrected the model’s failures across specific document types, jurisdictions, and practice areas. That feedback loop requires access to real legal workflows at enterprise scale, which is precisely what an open-source project lacks.
Citation verification infrastructure. The Stanford HAI study found that even the best legal AI tools hallucinate citations at significant rates — CoCounsel at 34%, Protégé at 17%. The difference between those rates and what raw models produce comes from integration with KeyCite and Shepard’s Citations — verification systems backed by decades of editorial curation. Westlaw’s database and LexisNexis’s 200 billion documents aren’t just large — they’re editorially maintained, with human lawyers verifying that citations are current, distinguishing overruled holdings from good law. No open-source project can replicate that corpus because the underlying data is proprietary. Will’s separate project OpenJuris tackles citation verification directly — and it’s the most interesting signal in the whole Mike story, because it’s going after the one moat that genuinely matters rather than the interface layer he already proved is commodity.
The Pricing Wall#
For firms that built the everyday stack from Part 1 of this series — Claude Team for reasoning, a citation service, Gemini Flash for volume extraction — Mike is a familiar proposition: a workflow skin on the same foundation models, adding a project interface and collaboration but not the privilege protections or institutional knowledge layer you already have. It competes with your Claude stack, not with Harvey’s domain expertise.
Harvey doesn’t publish pricing. Market intelligence from AI Vortex and industry sources estimates $1,200–$2,000+ per seat per month, with minimum commitments of 20+ seats and typical contract terms of 12–24 months. At the low end, that’s $288,000 per year before implementation, training, and integration costs. Enterprise deployments at large firms reportedly exceed $500,000 annually.
That pricing is rational for AmLaw 100 firms where AI cost is a rounding error on revenue. It’s exclusionary for the vast majority of the market. A 15-attorney litigation boutique doing $8 million in revenue isn’t spending $288,000 on a contract review tool — that’s 3.6% of gross revenue on a single software product.
Where the Calculation Flips#
The build-vs-buy calculation is firm-size dependent. Here’s what a 40-attorney firm doing 150 contract reviews, 30 deposition summaries, 20 research memos, and ongoing classification monthly would pay on each path:
| Path | Monthly Cost | Annual Cost | Notes |
|---|---|---|---|
| Harvey (enterprise) | $48,000–$80,000 | $576,000–$960,000 | 40 seats × $1,200–$2,000/seat |
| Claude Team + Midpage + Gemini | $3,200–$5,000 | $38,400–$60,000 | $25/seat (Team) + API + citation service |
| Mike (self-hosted) + cloud APIs | $500–$2,000 | $6,000–$24,000 | Server costs + API fees + maintenance |
| Mike (fully self-hosted w/ DeepSeek) | $200–$800 | $2,400–$9,600 | Hardware amortization + electricity |
Estimates assume stated task volumes. Harvey pricing from market intelligence; actual rates vary by firm. Hybrid path assumes competent development and maintenance. Publisher subscriptions may be required on both paths.

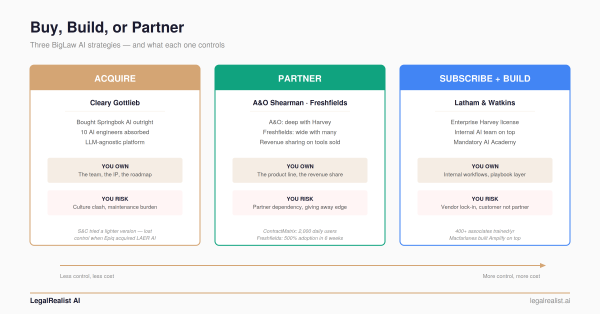
The flip point sits around 30–80 attorneys. Below that, Claude Team at ~$25/seat/month works because integration requirements are simple. Above that, SLAs, malpractice insurance review, and DMS integration make the vendor premium rational — Harvey’s cost is under 1% of revenue for a 500-attorney firm, and the Latham model applies: subscribe for general capabilities, build for differentiation. In the middle is where the hybrid stack earns its keep.
The Dynamic Competition That Matters#
Mike’s emergence coincides with a shift at the model layer that makes the open-source thesis viable — and illustrates how quickly competitive pressure reshapes the legal AI ecosystem.
DeepSeek-R1 matched frontier reasoning models at a fraction of the training cost. Llama 4 runs locally on consumer hardware. A single RTX 4090 can serve a 70B-parameter model to a small firm’s entire team using Ollama or vLLM. The performance gap between open-weight and closed-source models on classification, extraction, and summarization — the volume tasks that dominate legal workflows — has effectively closed (Epoch AI analysis).
The competitive pressure cascades through the ecosystem: cheaper models expose Application Layer markups, reproducible applications expose the layers beneath them, and only genuine domain expertise and proprietary data survive the scrutiny. What DeepSeek did to model pricing, Mike is attempting one layer up.

The Ecosystem Is Still Catching Up#
In 2003, a startup could download LAMP (Linux, Apache, MySQL, PHP) and build a web application without paying Microsoft or Oracle. The components were free and functional. What the startup couldn’t get was managed hosting, monitoring, security patches, and 24/7 support. That ecosystem matured predictably: Rackspace built managed LAMP hosting, then AWS made it invisible.
Legal AI is at the LAMP stage. The components exist — open-weight models, RAG frameworks, vector databases, and now Mike’s application interface. What doesn’t exist yet is managed legal AI infrastructure for firms that want open-source economics with enterprise reliability. Both BigLaw and boutiques are hiring AI engineers directly — A&O Shearman, Freshfields, and smaller firms are all recruiting — because the managed service ecosystem hasn’t caught up to the technology yet. Legal AI is heading for the same pattern. Mike and projects like it establish that the open-source components exist and work. The managed layer will follow.
What Mike Actually Tells You#
Mike is not production software. The AGPL license,1 the vibe-coded architecture, and the thin commit history suggest a project that proves a point rather than one positioned for adoption. But the point it proves matters.
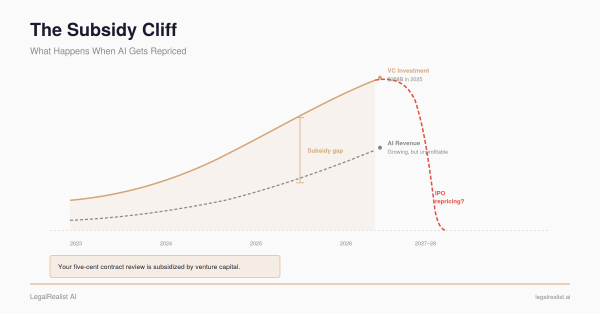
DeepSeek showed that frontier model performance could be achieved at a fraction of the training cost — and within months, every major lab cut prices. Mike demonstrates the same dynamic one layer up: the application interface is commodity software, reproducible in two weeks with an AI coding assistant. Together, they create a pricing pressure cascade — models getting cheaper from below, application layers getting reproducible from above — squeezing every vendor whose pricing assumes either layer is proprietary.
That’s the SaaSpocalypse thesis applied to legal tech. Not the end of enterprise legal AI — Harvey has its custom case law model, Thomson Reuters has Westlaw and KeyCite, LexisNexis has Shepard’s and 200 billion documents. Those moats are real. But perceived moats — the ones built on a proprietary-looking interface rather than proprietary data — are getting demolished overnight. And that demolition benefits the consumer of legal AI at every firm size. Pricing comes down. Transparency goes up. Firms that were priced out of the market a year ago now have viable alternatives.
That’s good for every firm evaluating legal AI, regardless of whether anyone deploys Mike. DeepSeek drives pricing pressure at the model layer. Open-source projects like Mike drive it at the Application Layer. Route accordingly.
In Suits, Harvey eventually helped Mike get his law degree. The open-source legal AI community is working on its equivalent — and the pricing pressure from that effort is already doing its job.
Further Reading#
- MikeOS. Self-hostable open-source legal AI.
- Mike on GitHub. Source code, AGPL-3.0 license.
- AI Counsel: Meet MikeOS. Launch coverage and Will’s background.
- Hacker News discussion. Community takes on privilege, architecture, and maturity.
- OpenJuris. Open-source citation verification from the same developer.
- Claude Team. The everyday stack foundation — $25/seat/month ($20 annual), with a DPA and no-training commitment under Anthropic’s Commercial Terms (true zero-data-retention requires the API).
- DeepSeek-R1 on Hugging Face. Open-weight reasoning model (MIT license).
- Ollama. Simplest way to run open-weight models locally.
- LangChain and LlamaIndex. RAG frameworks (both MIT-licensed).
- GNU AGPL-3.0. Mike’s license, with Section 13 on network use.
- Ropes & Gray: DeepSeek Legal Considerations. Data privacy analysis for self-hosted deployment.
- Harvey AI Pricing 2026 — AI Vortex. Market intelligence on cost structure.
- Stanford HAI: The AI Groundedness Problem. Citation hallucination rates across legal AI tools.
This is part two of the Legal AI Arms Race series on LegalRealist AI. Read Part 1: The $17 Billion Question. This post is intended for informational and educational purposes only and does not constitute legal advice. Product capabilities, pricing estimates, vendor claims, and licensing terms described here reflect publicly available information as of the publication date and are subject to rapid change. The licensing discussion is informational — consult IP counsel before making deployment decisions based on open-source license terms. The author has no commercial relationship with any vendor mentioned.
For comparison, the dominant open-source AI components all use permissive licenses: LangChain, LlamaIndex, Ollama, and DeepSeek-R1 are MIT. Llama 4 uses Meta’s custom license, permissive for most commercial use. The AGPL’s network-use provision (Section 13) is what distinguishes Mike’s license from these alternatives. ↩︎

{kind=link}
{kind=link}
{kind=link}