TL;DR
- Data miners now file nearly half of all qui tam suits, but DOJ cases dramatically outperform them. Since FY 2024, data miners have filed over 45% of qui tam complaints. Yet three-quarters of PPP settlements came from DOJ-initiated cases built on non-public data.
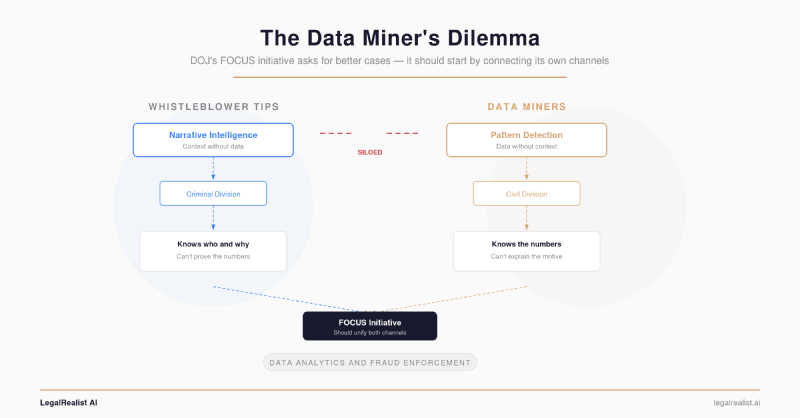
- DOJ runs two intake channels that don’t talk to each other. The Criminal Division’s Whistleblower Pilot collects insider tips. The Civil Division’s FOCUS initiative vets data miners. Whistleblowers have context without data; data miners have data without context.
- PPP is the proof of concept the government ran by accident. Journalists sued under FOIA. A court ordered data release. Within three years, serial relators were filing batches of qui tam suits — and no other fraud domain has replicated this because no other domain has released identified data at scale.
- DOJ can fix the data problem without Congress. Release pseudonymized datasets with consistent identifiers, connect whistleblower tips to data miner filings upstream, and clear the public disclosure bar for algorithmic analysis. None of these appear in FOCUS.
Today the DOJ announced the FOCUS initiative — Fraud Oversight through Careful Use of Statistics — inviting data miners to meet with the Civil Fraud Section to discuss their analytical capabilities. The accompanying memo is polite but pointed: the Department will “prioritize working with data miners who have demonstrated an investment in pre-filing diligence and commitment to analytical rigor.”
Translation: too many data miner complaints aren’t very good, and DOJ is tired of sorting through them. The name says it all — Fraud Oversight through Careful Use of Statistics. The acronym is the ask: focus your work, be more careful, use statistics properly. It’s a demand on data miners, not an offer to them.
But FOCUS addresses the wrong problem. The quality gap in data-driven qui tam suits isn’t primarily about analytical rigor — it’s about information. And the solution isn’t better algorithms on the same degraded public data. It’s connecting the two enforcement channels DOJ already runs: whistleblower tips that provide insider context, and data miner analytics that provide statistical evidence. Right now, those channels operate in separate silos. Bridging them is the enforcement multiplier nobody is building.
The Two Channels#
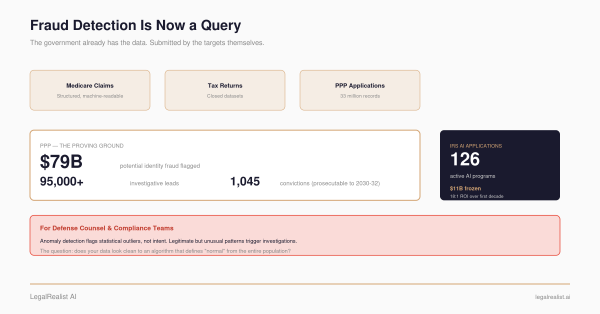
The numbers behind FOCUS tell the story. Whistleblowers filed 1,297 qui tam suits in FY 2025 — a record, up from 980 the prior year. Over 780 have been filed so far in the current fiscal year. The FOCUS memo reveals the breakdown: since FY 2024, data miners have filed more than 45% of all qui tam complaints. These aren’t insiders blowing the whistle. They’re analytics firms working on contingency, combing publicly available government data for statistical anomalies that suggest fraud.
Simultaneously, the Criminal Division’s Corporate Whistleblower Awards Pilot Program, launched in August 2024 and expanded in May 2025, collects insider tips on corporate misconduct — foreign bribery, financial institution fraud, healthcare fraud involving private insurers, government contracting fraud, and trade and customs violations. DOJ recently paid its first whistleblower award (WilmerHale coverage): $1 million for a tip leading to a $3.28 million criminal fine against EBLOCK Corporation.
These channels solve complementary halves of the same problem.
A whistleblower knows that their employer is submitting false Medicare claims. They know which billing codes are being inflated, who authorized the practice, and why it started — the scienter. What they typically don’t have is a statistical picture of how the conduct compares to industry norms, what the total false claims volume looks like, or how the pattern connects to similar conduct at affiliated entities.
A data miner can identify that a provider’s cardiac procedure billing runs three standard deviations above regional averages. They can flag that the provider’s ownership structure links to entities under investigation in other jurisdictions. What they can’t show is why the billing is false rather than merely unusual — whether the procedures were unnecessary, whether diagnoses were fabricated, whether anyone knew the claims were improper. Statistical outliers aren’t fraud. Scienter makes them fraud.
Each channel alone has a predictable failure mode. Whistleblower tips without data produce complaints that DOJ can’t corroborate efficiently — the insider says fraud exists, but proving it requires the same resource-intensive investigation DOJ would have conducted on its own. Data miner complaints without insider context produce what the FOCUS memo diplomatically calls low-quality filings: statistical anomalies dressed up as fraud allegations, without the “cogent investigative roadmap of facts to corroborate, witnesses to interview, and evidence to obtain” that DOJ says characterizes the best qui tams.
The FOCUS memo’s own numbers confirm the gap. Of approximately 840 PPP-related settlements and judgments totaling over $850 million, more than three-quarters came from DOJ-initiated cases — not from data miner qui tams. The government’s cases, built on non-public SBA data, IRS records, and cross-agency referrals, dramatically outperform outside filings. Overall, approximately 22% of all qui tams result in government intervention, and intervened cases produce the vast majority of recoveries.

The Missing Bridge#
The enforcement multiplier is obvious: match a whistleblower’s insider narrative to a data miner’s statistical evidence.
A compliance officer at a hospital chain reports that management is pressuring physicians to upcode cardiac procedures. That tip tells DOJ what to look for and who knew. A data miner independently finds that the same hospital chain’s cardiac billing deviates sharply from Medicare norms. That analysis tells DOJ how much the fraud costs and where the pattern extends across affiliates.
Neither filing alone would be a strong case. Together they give DOJ both the scienter (the insider’s knowledge of intent) and the falsity at scale (the statistical evidence of systematic overbilling). The whistleblower provides the context that transforms a statistical anomaly into an allegation of fraud. The data miner provides the quantification that transforms an insider anecdote into a case worth millions.
DOJ already shares data between civil and criminal divisions extensively — this isn’t a novel idea. The Yates Memo (2015) required “early and regular communication” between civil and criminal attorneys on corporate investigations. Documents produced in response to Civil Investigative Demands can be shared with criminal prosecutors by statute, and most U.S. Attorney’s Offices automatically share sealed qui tam complaints with their criminal division. Parallel civil-criminal proceedings are standard DOJ practice, and new AUSAs are trained on them at the National Advocacy Center.
The new National Fraud Enforcement Division (NFED), announced shortly before FOCUS, pushes further. It consolidates criminal fraud units under one assistant AG, directs the Civil Division to designate a liaison to the NFED, and creates a National Fraud Detection Center for proactive lead generation. The Office of Legal Policy has 120 days to recommend whether the Civil Division’s Fraud Section should be absorbed entirely.
But none of this existing coordination addresses the specific gap FOCUS creates. The civil-criminal data sharing infrastructure connects DOJ attorneys working on the same case. What doesn’t exist is a mechanism to connect a Criminal Division whistleblower tip about Company X to a Civil Division data miner filing about Company X before anyone recognizes they’re related. The Whistleblower Pilot and FOCUS are separate intake funnels. A whistleblower submits a tip to [email protected]. A data miner emails [email protected]. If both identify the same entity, that match depends on an attorney in one division happening to mention it to a colleague in the other — not on any systematic cross-referencing.
The NFED’s National Fraud Detection Center could be the right home for this matching function, but neither the NFED memo nor FOCUS mentions connecting the two intake streams. The plumbing exists for sharing data once a case is identified. It doesn’t exist for connecting signals that could identify a case.
The SEC’s Office of Market Intelligence offers a partial comparison — it cross-references 27,000 whistleblower tips per year against market surveillance data in a single pipeline. Financial markets are structurally different — securities fraud happens inside the data systems that monitor it, while healthcare fraud happens upstream of billing data. The SEC can catch insider trading from data alone. DOJ can’t catch Medicare upcoding from claims data alone — it needs someone who was in the room. That structural difference is exactly why bridging tips and data miners matters more for DOJ than it does for the SEC.
The Information Asymmetry#
The SEC comparison highlights a deeper problem: even with triangulation, data miners face a structural disadvantage in the data itself.
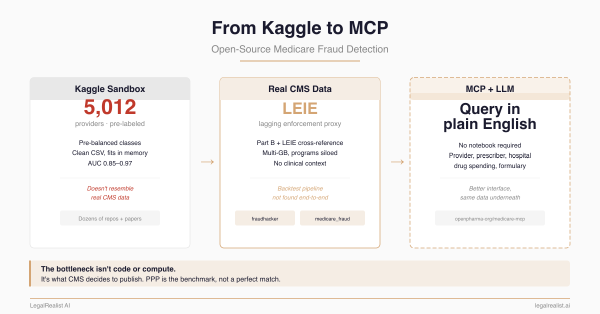
As we covered in The Government Already Has the Data, federal agencies sit on a closed, clean dataset of every transaction needed to find fraud. The IRS has every tax return. CMS has every Medicare claim with patient and provider identifiers. The SBA had every PPP loan application with full supporting documentation. DOJ cross-references these using Social Security numbers and EINs that connect a single entity across programs.
Data miners get the public residue:
Medicare claims. CMS releases de-identified public use files with directly identifiable information removed and potentially identifying variables recoded. A data miner can spot a billing outlier by provider type and region but can’t link that provider’s Medicare activity to their Medicaid claims, DEA prescribing records, or state licensing history. Research identifiable files exist but require formal data use agreements, research applications, and fees — designed for academics, not qui tam relators.
Federal spending. USAspending.gov publishes contract and grant data covering nearly 100 million contract actions over 45 years, but GAO has identified missing subaward information, duplicative records, and inconsistent standards across agencies. Monthly update cycles mean publicly visible records lag real-time activity by 30-90 days.
PPP loan data. The SBA’s public releases were unusually detailed — borrower names, amounts, NAICS codes — which is why PPP has been the proving ground for data miner qui tams. But the public data doesn’t include loan applications, borrower certifications, payroll documentation, or SBA review notes — the records DOJ uses to prove scienter. And critically, even this data wasn’t released voluntarily.
The Natural Experiment#
The FOCUS memo itself identifies PPP as the domain where data miners have been “particularly active” — and the reason is data.
The $850 million in PPP-related settlements reflects the scale of fraud in an $800 billion emergency program, not the impact of data miners specifically. More than three-quarters of the 840 settlements came from DOJ-initiated cases. Whether DOJ would have eventually found the remainder is unknowable — but beside the point.
What matters is who did the screening. Without data miners, DOJ attorneys sort through raw data themselves — or wait for tips that may or may not be actionable. With data miners, the analytical triage happens outside the Department, at the data miners’ own expense. The data miners absorb the cost of cross-referencing millions of loan records against corporate ownership databases, employment records, and state registrations. DOJ’s finite staff then evaluates pre-filtered leads rather than raw data. In a department that has issued over 1,000 Civil Investigative Demands in each of the last four years and is processing record qui tam volume, that’s the difference between sorting through haystacks and reviewing a shortlist of needles.
This is what FOCUS is trying to achieve — better-quality data miner filings that DOJ can act on efficiently. But it’s asking for better output without improving the inputs.
The SBA didn’t publish PPP loan data voluntarily. In May 2020, the Washington Post, New York Times, Bloomberg, Dow Jones, and ProPublica sued under FOIA for borrower names and loan amounts. The SBA resisted, initially releasing only loans above $150,000 — 87% of borrowers remained anonymous. In November 2020, Judge Boasberg ordered full release. The court pointed out that the PPP application itself warned borrowers their information would be subject to FOIA.
What followed wasn’t immediate. The first PPP settlement from an intervened data miner qui tam came in September 2022 — nearly two years after the data release. By FY 2023, serial data mining relators like GNGH2 and Relator LLC were filing batches of affiliation-theory cases — cross-referencing borrower names against state corporate registrations and employment databases to identify companies that exceeded the 500-employee eligibility threshold when affiliate employees were counted. These cases couldn’t exist without identified borrower data, because the entire theory depends on matching a borrower’s identity to its corporate ownership structure.

PPP is the only federal fraud domain with identified public data at scale, and the only domain where data miners have become a significant enforcement force. Winston & Strawn, Crowell & Moring, and the National Law Review all trace the connection directly. Compare Medicare: CMS de-identifies its public claims data, and data miner qui tams targeting healthcare billing are correspondingly rare. Releasing the data didn’t guarantee better cases. It guaranteed that DOJ wasn’t the only one doing the work.
This is where the triangulation argument becomes concrete. A data miner can’t access full provider-level Medicare data, but a whistleblower inside the provider can describe the specific billing practices that explain the anomaly. The insider fills the gap that de-identification creates. The data miner fills the gap that anecdotal evidence creates. The combination produces something neither could produce alone — and something closer to what DOJ builds internally from its full datasets.
The Public Disclosure Bar Trap#
Data miners face one more obstacle that makes triangulation not just useful but legally necessary: the public disclosure bar.
The FCA prohibits qui tam suits based on information already publicly disclosed — unless the relator is an “original source” with independent knowledge that “materially adds” to the disclosure. For data miners, every input is potentially a public disclosure. Courts are split on whether algorithmic analysis qualifies, and AI compounds the ambiguity because generative tools typically don’t cite specific sources.
Combining data miner analysis with whistleblower information provides a potential solution — an insider’s non-public knowledge is, by definition, not publicly disclosed. A complaint built on the intersection of public analysis and private knowledge is far more defensible against the bar than data mining alone. Another reason bridging DOJ’s two channels matters.
There’s also a reward problem DOJ can’t fix on its own. FCA qui tam awards run 15-30% of recovery — but only if DOJ intervenes, and only 22% of qui tams get intervention. The Criminal Division’s Whistleblower Pilot awards are entirely discretionary. Changing this requires Congress.
What DOJ Can Do#
What DOJ can fix is the data. To the extent it wants outsiders to connect noisy datasets — to do the triangulation work that turns statistical anomalies into actionable leads — it needs to provide data that’s actually usable for cross-referencing. Three things:
Release pseudonymized or anonymized datasets with consistent identifiers. The data doesn’t need to be fully identified to be useful for matching. What data miners need is the ability to connect a provider’s billing pattern to their corporate affiliations to their licensing history — and that requires consistent entity identifiers across datasets, even if the identifiers are pseudonymized. CMS already produces synthetic public use files for research. Provider-level billing data with patient identifiers removed but consistent provider keys retained would enable the cross-referencing that turns outliers into leads. Right now, each public dataset is de-identified independently — a provider in CMS data can’t be linked to the same provider in OIG exclusion data or state licensing records. That fragmentation is what makes the public data useless for the exact kind of work FOCUS demands.
Connect whistleblower tips to data miner filings. DOJ already shares case data across divisions once an investigation is open. What’s missing is upstream matching — a systematic check, potentially housed in the NFED’s new National Fraud Detection Center, that cross-references entity names from Whistleblower Pilot submissions against entities flagged in data miner qui tams. This doesn’t require sharing protected case details — just running a match on company names and provider identifiers across two intake databases.
Clear the legal obstacles for the analysts you want. DOJ has the authority to oppose the public disclosure defense in specific cases. A blanket policy statement that DOJ will generally oppose the bar when algorithmic analysis materially adds to raw data would reduce litigation risk for sophisticated data miners and signal that the Department values analytical work — not just insider knowledge.
None of these steps appear in today’s FOCUS announcement.
The Pattern Across the Series#
This article completes a triangle.
In The Government Already Has the Data, we showed that federal agencies detect fraud by running queries against clean, closed datasets — where anomalies are real signals. In Following the Money, we showed that outside investigators working with noisy, open-set data need triangulation — cross-referencing multiple weak signals — to find leads that no single source reveals. Today’s FOCUS announcement sits at the intersection: DOJ is asking outside data miners to approach the quality of its internal analytics, using data that’s systematically degraded from what it holds.
The PPP experience answered the question DOJ isn’t asking. When a court forced the SBA to release identified loan data, data miners absorbed analytical work that DOJ would otherwise have had to staff internally — screening millions of records, cross-referencing corporate affiliations, and surfacing leads that DOJ attorneys could evaluate rather than generate. The government didn’t design this outcome. Journalists litigated for it. But it worked.
FOCUS asks data miners to get better. The PPP precedent suggests the government should give them something to work with.
Further Reading#
- FOCUS Initiative Announcement and Memo (DOJ). The press release and full guidance document.
- DOJ Corporate Whistleblower Awards Pilot Program. The Criminal Division’s parallel intake channel for insider tips.
- DOJ FCA FY 2025 Statistics. Record $6.8 billion in recoveries and 1,297 qui tam filings.
- DOJ Continues FCA Enforcement of PPP Loans (Winston & Strawn). Analysis of the data miner relator phenomenon and PPP enforcement trends.
- AI Data Mining and PPP False Claims Act Cases (National Law Review). How AI tools are lowering the barrier to data-driven qui tam suits.
- Artificial Intelligence, the False Claims Act, and the Public Disclosure Bar (Wiley). The legal challenges at the intersection of AI, public data, and FCA enforcement.
- Data Mining Relators: FCA Cases Based on Government Data (Alston & Bird). Early analysis of the data mining wave in qui tam litigation.
- DOJ Signals Continued Aggressive FCA Enforcement (Skadden). Key takeaways from the latest Qui Tam Conference.
- FCA FY 2025 Key Takeaways (Ropes & Gray). Detailed breakdown of qui tam recovery statistics.
- DOJ Is Serious About New Criminal Whistleblower Programs (Perkins Coie). Coverage of the first whistleblower award and program expansion.
- SEC Whistleblower Program. Comparative model: mandatory awards, integrated tip-to-surveillance pipeline.
- Integra Med Analytics v. Providence Health (C.D. Cal. 2019). Key ruling on data analytics and the public disclosure bar.
- Court Orders Public Release of PPP Data (ASPPA). Judge Boasberg’s order forcing SBA to release borrower-level loan data.
- Washington Post et al. v. SBA (FOIA Lawsuit). The litigation that forced PPP data transparency.
- CMS Public Use Files. The de-identified Medicare claims data available to data miners.
This post is part of the Data Analytics and Fraud series on LegalRealist AI. It is intended for informational and educational purposes only and does not constitute legal advice. The False Claims Act, qui tam provisions, and the public disclosure bar are complex statutory and case law areas; the analysis here is for informational purposes and should not be relied on for filing decisions. Enforcement statistics and data availability described here reflect publicly available information as of the publication date and are subject to change. Laws governing fraud enforcement and data privacy vary by jurisdiction.