TL;DR
- The model inside your AI tools is likely Chinese-built. One venture capital estimate puts the share of US AI startups using Chinese base models at roughly 80%. Cursor’s $29-billion coding assistant was built on a Chinese model it didn’t disclose.
- Chinese labs are pioneering the techniques everyone else adopts. MLA, GRPO, fine-grained MoE, and FP8 training originated in Chinese labs and were shared in full technical detail. Western closed labs put out announcements; Chinese labs share the engineering.
- Chinese models are the default — locally and via API. They dominate local deployment (most-downloaded on Hugging Face) and undercut Western API pricing by roughly 10x. GLM-5 trained a 744B frontier model entirely on Huawei Ascend chips — zero NVIDIA hardware.
- Chinese labs tipped the balance toward open models and democratized the technology. DeepSeek V4 Pro matches frontier closed models at roughly 10x lower input cost. Chinese models now account for 61% of token consumption among the top ten models on the world’s largest API aggregator.
- You can run capable models on a laptop. A 4-bit quantized
Qwen3.6-30Bruns locally on a MacBook — no API, no cloud, no data leaving your machine. Not frontier-class, but genuinely useful for everyday coding and drafting.
Corrections & Updates
- June 7, 2026 (pricing/model update): DeepSeek raised V4-Pro’s API price after publication — a launch promo became permanent in May 2026, so input is now ~$0.435/M and output ~$0.87/M, not the ~$0.145/M originally cited. Against that June 7 Western comparison set (Claude Opus 4.8 and GPT-5.5, both $5/M input) that’s roughly 10–11x cheaper on input rather than the larger multiple stated. Cursor’s coding assistant was built on Kimi K2.5 (not K2.6). Benchmark comparisons to Claude Opus 4.5/4.6 and GPT-5.4 elsewhere in the post are left as accurate point-in-time results from each model’s release.
One Andreessen Horowitz partner estimated that roughly 80% of US AI startups use Chinese base models for derivative development — a figure cited in a March 2026 report by the U.S.-China Economic and Security Review Commission (USCC). On OpenRouter, the world’s largest AI model API aggregator, Chinese models accounted for 61% of total Token consumption among the platform’s top ten models in February 2026. Four of the top five most-used models globally were Chinese.
The “customized AI” your vendor built is likely running on a Foundation Model trained in Hangzhou, Beijing, or Shenzhen. That’s not a scandal. It’s the state of the industry.
This post covers the Chinese labs that matter, the technical innovations they’ve pioneered, and why those innovations are pushing the entire field forward faster than any single Western lab could on its own. (For background on how foundation models work, pricing, and benchmarks, see The Foundation.)
The Four Labs That Matter#
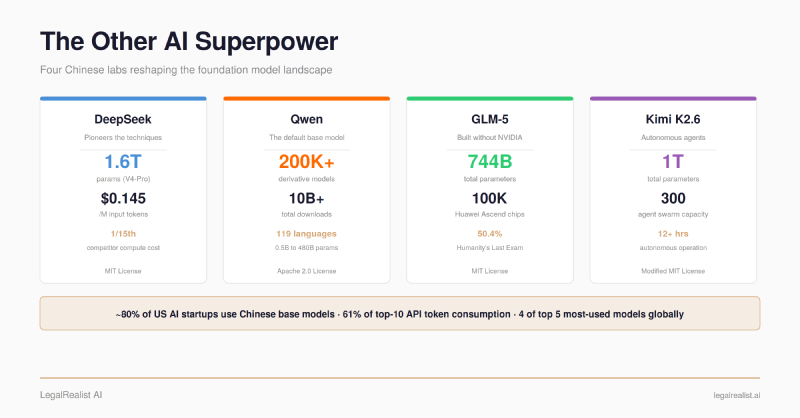
DeepSeek#
DeepSeek is the lab that forced the world to reconsider what open models could do. Founded in 2023 and funded by the quantitative hedge fund High-Flyer, DeepSeek operates without public shareholders or external investor pressure — an independence that lets it prioritize capability research over monetization.
The inflection point came in January 2025, when DeepSeek released R1, a reasoning model that matched or exceeded top closed-source models on mathematics, coding, and complex reasoning
benchmarks. DeepSeek reported that the final training runs cost under $6 million in GPU compute. That figure covers compute rental for the successful runs, not the billion-dollar-plus infrastructure investment, failed experiments, or staff that made them possible. But in terms of compute per training run, the cost was roughly one-fifteenth what competitors spent to reach comparable performance. Time Magazine named R1 one of the Best Inventions of 2025. The model was released under an MIT license — anyone can download it, run it, modify it, and deploy it commercially.
On April 24, 2026, DeepSeek released a preview of V4, its latest generation. V4-Pro carries 1.6 trillion total parameters with 49 billion active per
Token — the largest
open-weight model released to date. V4-Flash offers a leaner 284 billion total with 13 billion active for cost-sensitive workloads. Both support a one-million-
Token
Context Window and ship under the MIT license. At $0.435 per million input
tokens — after a launch promo was made permanent in May 2026 — V4-Pro was roughly 11x cheaper on input than the June 7 comparison prices for GPT-5.5 or Claude Opus 4.8.
What sets DeepSeek apart is its research culture. Every major architectural innovation — Multi-Head Latent Attention, fine-grained Mixture of Experts, Group Relative Policy Optimization, multi-token prediction, FP8 training — was shared in detailed technical reports with full architecture specifications, training procedures, hyperparameters, and ablation studies. Not an ad for a new product. Not a “system card” describing safety evaluations. The actual engineering, in enough detail that other labs reproduced the work within weeks. Western closed labs put out announcements; DeepSeek shares the engineering.
Alibaba (Qwen)#
Alibaba’s Qwen is the most widely deployed open-source
LLM family in the world. Over 200,000 derivative models and 10 billion downloads — the first open-source
large language model to reach either milestone. One model alone, Qwen2.5-1.5B-Instruct, has 8.85 million downloads on Hugging Face. Qwen isn’t competing with ChatGPT for end users — it’s competing with Meta’s Llama, Google’s Gemma 4, and Mistral to be the default base model that every other company
fine-tunes, rebrands, and sells. It’s winning.
What makes the family useful for downstream builders is its range. Parameter sizes span from 0.5 billion (runs on a phone) to 397 billion, with specialized variants tuned for math, coding, vision, and instruction-following across 119 languages. Qwen3 (April 2025) introduced a hybrid reasoning mode — the same model switches between “fast thinking” for simple queries and “deep thinking” for complex analysis, eliminating the need for separate models for different task types. Qwen3.5 (February 2026) scaled to a 397B-parameter
MoE architecture that rivals Gemini 3 Pro in
benchmarks. The Qwen3-Coder family — up to 480B parameters with 35B active — is purpose-built for agentic coding, with a 256K
Context Window and state-of-the-art performance on SWE-Bench Verified among open-source models. The smaller Qwen3-Coder-Next activates only 3 billion of its 80 billion parameters — achieving performance comparable to Claude Sonnet 4.5 on coding
benchmarks while running on consumer hardware.
I run Qwen3.6-30B at 4-bit quantization on my MacBook. It autocompletes code as I type in my editor — no API call, no cloud, no data leaving the machine. A 30-billion-parameter model, built by a Chinese tech giant, running on a laptop I can take anywhere. Two years ago that sentence would have been science fiction.
Z.ai / Zhipu AI (GLM)#
Z.ai (formerly Zhipu AI), a Tsinghua University spinoff founded in 2019, proved something the Western AI establishment considered impractical: training a frontier-class model entirely without NVIDIA.
GLM-5, released February 11, 2026, is a 744-billion-parameter
MoE model with 44 billion active per
Token, a 200,000-
Token
Context Window, and an MIT license. It was trained entirely on 100,000 Huawei Ascend 910B chips using the MindSpore framework. Zero NVIDIA hardware at any point in training. The first frontier-class model built without any US-manufactured silicon — proof that the entire AI stack, from chip to trained model, can be built outside the NVIDIA ecosystem.
At release, GLM-5 scored 50.4% on Humanity’s Last Exam, then the highest result reported, surpassing Claude Opus 4.5 and GPT-5.2. It reached 77.8% on SWE-bench. The model uses DeepSeek Sparse Attention for efficient long-sequence processing — another case of Chinese labs building on each other’s shared innovations.
Moonshot AI (Kimi)#
The other three labs build models you prompt. Moonshot AI builds models that run autonomously.
Kimi K2.6 (April 2026) is a one-trillion-parameter
MoE model with 32 billion active per
Token and a 256K
Context Window, designed for
agentic AI — autonomous multi-step task execution without human intervention. Its Agent Swarm system coordinates up to 300 specialized sub-agents across 4,000 steps in a single run. In one published test, K2.6 ran continuously for 12+ hours on a coding task, making over 4,000 tool calls — porting an inference engine to a niche programming language, optimizing it through 14 iterations, and increasing throughput by roughly 13x.
Kimi tops GPT-5.4 on agentic coding benchmarks (SWE-Bench Pro 58.6 vs. 57.7) and scored 54.0 on Humanity’s Last Exam with tools — leading every model in the comparison, including GPT-5.4, Claude Opus 4.6, and Gemini 3.1 Pro. The weights are open under a Modified MIT license. Cursor quietly built its $29-billion coding assistant on an earlier Kimi model, K2.5 — a fact that didn’t come out until a developer intercepted the model ID in an API call.
Five major releases between the original K2 (July 2025) and K2.6 (April 2026). Each pushed a specific capability forward: K2 established the trillion-parameter MoE baseline; K2-Thinking introduced Chain-of-Thought reasoning; K2.5 added Multimodal and Agent Swarm; K2.6 consolidated everything around long-horizon autonomous execution. That pace — a major release roughly every month — is itself a product of the open research culture these labs share.
The Technical Playbook#
Chinese labs have a distinctive advantage that has nothing to do with data or scale: they are exceptionally good at architecture optimization. Constrained by US export controls that restrict access to NVIDIA’s best chips, Chinese researchers responded not by waiting for better hardware but by rethinking how models use the hardware they have. The constraint became a catalyst. The result is a set of innovations rooted in applied mathematics and engineering efficiency — techniques that squeeze more capability out of every GPU hour and every byte of memory.
Western closed labs treat these techniques as trade secrets. Chinese labs share them — in full technical detail, with training procedures, ablation studies, and reproducible results. The four innovations below didn’t just come from Chinese labs. They were pioneered there and handed to the global AI community in enough detail to use immediately.
Mixture of Experts: The Efficiency Engine#
Every large language model has parameters — the numerical weights the model learned during training. A conventional “dense” model activates all of its parameters for every Token it processes. A Mixture of Experts ( MoE) model divides those parameters into specialized sub-networks (“experts”) and activates only a handful per Token.
DeepSeek’s contribution was making this architecture radically more fine-grained. Where earlier
MoE models used 8 or 16 large experts, DeepSeek uses 256 small ones, routing each
Token to the 8 most relevant plus one shared expert. The result: V4-Pro has 1.6 trillion total parameters — the knowledge capacity of an enormous model — but activates only 49 billion per
Token, keeping
Inference costs comparable to a model a fraction of its size. That’s the core reason DeepSeek can price V4-Pro at a fraction of Claude Opus 4.6 — and why tools built on
MoE models can offer lower per-task pricing without sacrificing capability.

GRPO: Reasoning Without the Training Tax#
Teaching a model to reason — not just predict the next word, but work through multi-step problems — has traditionally required reinforcement learning from human feedback ( RLHF). Standard RLHF needs two models running simultaneously: the model being trained and a separate “critic” model that evaluates its outputs. That doubles the compute.
DeepSeek’s Group Relative Policy Optimization (GRPO), shared in the DeepSeekMath paper in 2024, eliminates the critic model entirely. Instead of training a second model to judge quality, GRPO generates a group of candidate responses, scores them against each other using rule-based rewards (did it get the math right? did it follow the format?), and optimizes based on relative rankings within the group. The model learns to reason by comparing its own outputs, not by consulting an external judge. Think of it as replacing an outside consultant who grades every draft with a system where competing drafts are ranked against each other and the strongest reasoning rises — no external reviewer required.
DeepSeek shared the full algorithm, reward functions, and training curves. Within months, GRPO variants appeared from ByteDance, Alibaba, and independent researchers worldwide. This is the single biggest reason R1’s final training run could cost what it did.
Multi-Head Latent Attention: Compressing the Memory#
Every Transformer-based model maintains a key-value (KV) cache — a memory structure that stores information about every Token the model has processed so far. As the Context Window grows (from 8K to 128K to 1M tokens), this cache grows proportionally, consuming GPU memory and driving up cost. At one million tokens, a naive implementation would require more memory for the cache alone than most servers have available.
DeepSeek’s Multi-Head Latent Attention (MLA), introduced in V2, compresses the KV cache into a much smaller latent representation — dramatically reducing memory requirements without sacrificing the model’s ability to connect information across distant parts of a document. MLA solved the memory side of long-context
Inference. But memory is only half the cost — the other half is compute. That’s where V4’s sparse attention architecture comes in.
Sparse Attention: Not Every Token Needs Full Treatment#
In a standard
Transformer, every new
Token attends to every previous
Token — the compute cost grows quadratically with sequence length. At 8K
tokens, that’s manageable. At one million, it’s ruinous. DeepSeek V4 introduced a hybrid approach: Compressed Sparse Attention (CSA) for most layers, which clusters earlier
tokens into compressed representations so the model doesn’t reprocess the full history at every step, and Heavily Compressed Attention (HCA) for a subset of layers, which compresses even more aggressively for long-range dependencies. The model decides how much attention each layer needs to pay, and to what granularity, rather than treating every
Token as equally important everywhere.
The engineering result: at the one-million-
Token setting, V4-Pro requires only 27% of the single-token inference FLOPs of V3.2. Combined with MLA’s KV cache compression (10% of V3 levels), the total cost of running a million-
Token query dropped by roughly an order of magnitude between model generations. That’s not a tuning improvement. That’s an architectural redesign, shared in full, that every other lab can now build on.
A model that can hold a million tokens in context but costs $50 per query is a demo. A model that holds a million tokens at a fraction of that cost is a workflow. MLA and sparse attention together are what made the second sentence true.
Two additional innovations compound these savings. Multi-token prediction (MTP), introduced in DeepSeek V3, trains the model to predict several
tokens ahead simultaneously, improving both sample efficiency during training and generation speed at
Inference. FP8 training uses 8-bit floating-point precision instead of the standard 16-bit, doubling compute throughput and halving memory — same hardware, twice the capacity. Both techniques are shared and reproducible.
What Democratization Actually Looks Like#
Every innovation above was shared in a research paper with full architecture specifications — not a press release, not a Benchmark table, not an ad for a new product. The models that implement them ship under permissive open licenses. Download, fine-tune, deploy commercially, no fee, no permission required.
Chinese labs have inverted the model where frontier innovation stays locked behind an API. DeepSeek pioneers a technique. Within weeks, Alibaba adapts it. Moonshot builds on the adaptation. Independent researchers worldwide reproduce the results and push them further. A startup in São Paulo
fine-tunes a DeepSeek derivative for Brazilian contract law. A team in Berlin builds a medical reasoning model on Qwen’s base. I download a 4-bit Qwen3.6-30B and run it on my MacBook for coding. The innovations compound across the ecosystem instead of staying behind one company’s API wall.
Before Chinese labs began sharing their work at this scale, open-weight models like Meta’s Llama, Google’s Gemma, and Mistral’s releases were the primary open alternatives to closed frontier models — capable, but consistently a tier behind the best closed systems. Chinese labs tipped the balance. The performance gap between open and closed models on knowledge and reasoning benchmarks narrowed from roughly 18 percentage points in late 2023 to effectively zero by early 2026. That convergence wasn’t inevitable. It was engineered — through shared research, permissive licensing, and a competitive ecosystem where every innovation is immediately available to every participant.
Open Source as Strategy#
Chinese models have become the default at both ends of the deployment spectrum. For local use, they dominate: the most-downloaded model families on Hugging Face are Chinese, and the ecosystem of quantized, consumer-hardware-friendly models runs overwhelmingly on Qwen, DeepSeek, and their derivatives. For API use, they’re the cheapest frontier-class option available — DeepSeek V4-Pro at $0.435 per million input
tokens (after its May 2026 price cut) undercuts Western equivalents by roughly 10x. And with Z.ai’s GLM-5 trained entirely on Huawei Ascend chips and Huawei scaling to nearly 800,000 next-generation AI chips for 2026, even the hardware dependency on NVIDIA is eroding.
Chinese open-source models grew from approximately 1.2% of global usage in late 2024 to nearly 30% by the end of 2025, according to data from OpenRouter and Andreessen Horowitz. China’s daily AI Token usage reached 140 trillion in March 2026 — up from 100 billion at the start of 2024, a more than 1,000-fold increase in two years.

The USCC’s “Two Loops” report describes two reinforcing feedback loops driving this growth. The first is an open technical commons where labs build on each other’s work — DeepSeek’s R1-Distill-Qwen-32B, a derivative of an Alibaba model that outperforms the original on certain
benchmarks, is the pattern in action. The second is global diffusion: permissive licensing creates adoption, which generates usage data that feeds back into the next model iteration. Even companies like Airbnb use Alibaba’s Qwen for customer service.
As MIT Technology Review noted: “Even amid growing US-China antagonism, Chinese AI firms’ near-unanimous embrace of open source has earned them goodwill in the global AI community and a long-term trust advantage. In 2026, expect more Silicon Valley apps to quietly ship on top of Chinese open models.”
The adoption isn’t abstract. Perplexity integrated DeepSeek R1 into its Deep Research engine, then released R1-1776, a decensored version stripped of Beijing’s content filters. Stanford researchers — including Fei-Fei Li, often called the “godmother of AI” — built their S1 reasoning model on top of Alibaba’s Qwen for under $50 in training cost. A top research product and a leading Stanford lab, both running on Chinese open-weight foundations.
The competitive dynamics cut in every direction. Other Chinese labs that had been closed or uncertain about open-source — including Zhipu’s GLM and Moonshot’s Kimi — followed DeepSeek’s lead. The competition has also pushed American firms to open up: OpenAI released gpt-oss, its first
open-weight models, under Apache 2.0. Google shipped Gemma 4. The Allen Institute for AI released Olmo 3.
The strategy is not without controversy. Anthropic has alleged that Chinese labs conducted “industrial-scale distillation attacks,” using fraudulent accounts and proxy services to extract knowledge from Claude and ChatGPT. The USCC calls this a paradox: building domestic chip independence while relying on knowledge extracted from Western models via distillation. The dispute is active and unresolved.
Chinese models are also trained under domestic content moderation requirements imposed by Beijing. Outputs on politically sensitive topics — Taiwan, Tiananmen, Xinjiang, Hong Kong — may be filtered, deflected, or inaccurate. For most coding, analysis, and drafting work, this has no practical effect. For work touching Chinese politics or human rights, it’s a factor worth testing before deployment.
The Landscape Is No Longer One-Sided#
Eighteen months ago, the frontier model conversation was straightforward: OpenAI led, Anthropic and Google competed, and Chinese models were a tier behind. That framing is obsolete.
Chinese labs now pioneer the architectural innovations that the rest of the field adopts, release frontier-class models under the most permissive open licenses available, train them on domestic hardware that wasn’t supposed to be capable of the task, and price API access at a fraction of Western equivalents. They tipped the balance from closed to open and democratized access to capabilities that were previously locked behind a handful of Western APIs. The field is moving faster because of it — and the models are getting cheaper, more capable, and more accessible for everyone.
Further Reading#
- Two Loops: How China’s Open AI Strategy Reinforces Its Industrial Dominance. USCC research report, March 2026.
- DeepSeek V4 on Hugging Face. Model weights, technical report, and architecture details.
- Qwen Model Family on GitHub. Alibaba’s open-source model repository.
- Qwen3-Coder on GitHub. Alibaba’s agentic coding model family.
- GLM-5: How China Trained a Frontier Model Without NVIDIA. Let’s Data Science technical analysis.
- Kimi K2.6 Release. Moonshot AI’s agentic model with 300-agent swarm orchestration.
- Cursor Built on Kimi K2.5. TechCrunch on the Composer 2 disclosure.
- What’s Next for AI in 2026. MIT Technology Review on the Chinese open-source wave.
- AI Export Controls Are Not the Best Bargaining Chip. Chatham House analysis of export control limitations.
- Ranking the Chinese Open Model Builders. Interconnects survey of 19 Chinese AI labs.
- DeepSeek: Paradigm Shifts and Technical Evolution. IEEE survey of DeepSeek’s architectural innovations.
This post is part of the AI Geopolitics series on LegalRealist AI. It is intended for informational and educational purposes only and does not constitute legal advice. AI capabilities, pricing, benchmark results, and geopolitical dynamics described here reflect publicly available information as of the publication date and are subject to rapid change. Laws governing AI use, data residency, and export controls vary by jurisdiction.