TL;DR
- We’re summoning ghosts, not building intelligence — and ghosts can’t count the r’s in “strawberry.” Andrej Karpathy’s metaphor captures what LLMs are: statistical distillations of humanity’s text, fluent in the patterns of language but empty of what language refers to.
- Hallucination is syntax without semantics. A hallucination is a syntactically sound sentence whose semantic truth value in the world is false. The model has no way to tell the difference, because the difference is semantic.
- Code escapes because it has truth conditions you can test. An LLM can write correct Python to count the r’s in “strawberry” but can’t count them itself. Code has a compiler. Law doesn’t.
- Legal reasoning is where the gap is widest. In Loper Bright, the Supreme Court couldn’t agree on what ambiguity means. Sometimes there’s no factual truth to find — the answer is the output of a political process.
- Animals have world models. Ghosts don’t. LeCun, Li, and Karpathy are trying to build animals. You can’t get from syntax to semantics by adding more syntax.
- LLMs are still extraordinary at legal work — the work that is linguistic data processing. The limitation shows up where the work stops being about language and starts being about what language refers to.
Andrej Karpathy — founding member of OpenAI, former director of AI at Tesla, one of the people who built the technology everyone is now arguing about — has a phrase for what large language models actually are. We’re “summoning ghosts, not building animals.”
Animals learn from reality — a child understands that objects fall and surfaces are hot long before learning to speak. Language comes later, as a layer on top of grounded experience. LLMs do it backwards. They learn language without ever having the experience that language refers to. As Karpathy writes, they are “imperfect replicas, a kind of statistical distillation of humanity’s documents.” Ghosts.
A ghost can’t see a strawberry. It has processed millions of sentences containing the word but the word is a Token — a statistical unit — not a fruit. Ask the ghost how many r’s are in “strawberry” and it fails, because the question requires seeing actual letters, and the ghost sees only patterns in tokens.
That same ghost can draft a motion to compel that reads like it was written by a litigator with twenty years of experience. It can analyze a statute with the vocabulary of a senior regulatory partner. It can produce a case citation in perfect Bluebook format — volume, reporter, page, court, year — without any of it referring to a real case. The form is flawless. The substance may be false. And the ghost has no way to tell the difference, because distinguishing true from false requires access to what the words refer to, and the ghost only has the words.
This is why LLMs hallucinate. Not because of a bug that better engineering will fix, but because of what they are.
Ghosts Can’t See Strawberries#
OpenAI reportedly code-named its o1 reasoning model “Strawberry” because solving the r-counting problem was an internal benchmark. The question is trivially easy for a child who can spell. It stumped the most powerful AI systems on the planet. The reason illuminates everything that follows.
LLMs don’t process characters. They process tokens — subword units that a
Transformer architecture uses as its basic building blocks. OpenAI’s tokenizer splits “strawberry” into three tokens: str, aw, and berry. The model never sees the individual letters. It sees three chunks and predicts what token sequence is most likely to follow a question about counting.
Research confirms that tokenization is the primary driver — and that even chain-of-thought prompting doesn’t fix it, because the reasoning itself operates on tokens, not characters.
The model isn’t failing to count. It was never counting. It’s predicting what the answer to a counting question probably looks like, based on patterns in its training data. When it says “two,” it’s not wrong because it miscounted — it’s wrong because counting isn’t what it does.
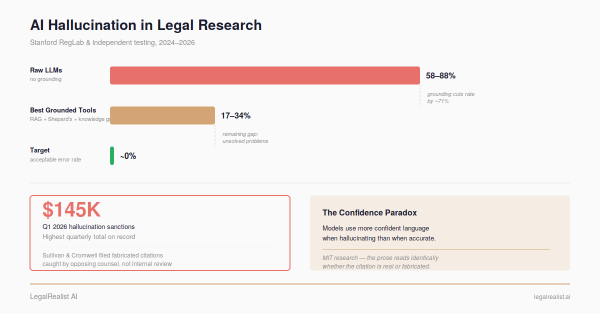
Now consider the parallel. When an LLM produces a citation in a legal brief — say, Smith v. Jones, 547 F.3d 892 (7th Cir. 2008) — it isn’t retrieving a case from a database. It’s predicting what a plausible citation looks like: what sequence of tokens is statistically likely after “See, e.g.,” in a brief about employment discrimination. The model produces citations that look exactly right — correct format, plausible reporter volume, appropriate court. Whether they refer to real cases is a question it has no mechanism to answer. Stanford RegLab found that on identifying a court’s core holding, models hallucinated at least 75% of the time.
The strawberry problem is the simplest instance of the gap — even character-level Grounding is absent. Legal Hallucination is a deeper instance — world knowledge, jurisdictional context, and human judgment are absent. Same gap, different depth. But the mechanism is identical: the model produces text that is syntactically well-formed and may be semantically false, with no internal signal distinguishing one from the other.
Syntax Without Semantics#
Syntax is the structure and rules governing how symbols are arranged — grammar, pattern, form. Semantics is meaning — what those symbols refer to in the world. The distinction is old. Its application to LLMs is new.
LLMs are the most powerful syntax engines ever built. They know that “shall” in a statute behaves differently from “may,” that “notwithstanding” signals an override, that “includes” sometimes means “includes but is not limited to” and sometimes doesn’t. They know that a motion to compel looks different from a client memo.
What they don’t have is a model of what any of it means. When an LLM uses the phrase “waters of the United States” in a regulatory analysis, it’s placing those words because they’re statistically likely in that context — not because it has any conception of which wetlands, tributaries, or drainage ditches a particular court would include under that phrase. When it produces a case citation, it’s generating a pattern that matches the form of a citation. It has no semantic model that connects that pattern to an actual case, an actual holding, an actual court.
A hallucination is a syntactically sound sentence whose semantic truth value in the world is false. The model has no way to tell the difference between a correct output and a hallucination, because the difference is semantic, and it has no semantic model.

Whether scale and architectural refinements will eventually produce something closer to genuine understanding is an open question. There’s evidence it might: researchers at Harvard trained a GPT-style model on nothing but Othello move sequences and found it had developed an internal representation of the board — inferring the state of the game from patterns in the data, without ever being shown a board. The model went from syntax to something that looks like semantics. But Othello is a closed system with fixed rules and complete information. The “world” behind a Supreme Court opinion — legislative intent, institutional competence, separation of powers — is open-ended and partially unobservable. Whether emergent internal modeling scales from game boards to courtrooms is the question that separates the optimists from the skeptics. For now, the gap is where hallucinations live.
Why Code Escapes#
In a formal programming language, the gap between syntax and semantics is as narrow as it gets. x = 5 + 3 has exactly one interpretation. No ambiguity, no context-dependence, no external world required. Code
Hallucination exists —
LLMs produce buggy code regularly — but code errors are catchable: a compiler, a test suite, a runtime exception closes the loop. Legal
Hallucination has no equivalent verifier.
This distinction has three consequences:
Verification is automatic. A compiler checks whether the code runs. A test suite checks whether it does what you asked. Truth in code is pragmatic — does it work? — and that pragmatic truth is testable. No test suite tells you whether a statutory analysis is right.
The feedback loop is tight. When training models, code provides an unusually clean signal. Right and wrong are often binary. This is part of why RLHF works better for coding than for open-ended language tasks — you don’t need a human evaluator to judge whether a sort function works. You need test cases.
The domain is self-contained. Writing a sorting algorithm doesn’t require understanding gravity, social dynamics, or what “reasonable” means. The entire universe of relevant facts is encoded in the formal language itself.
This is why an LLM can write correct code to count the r’s in “strawberry” but can’t count them directly. The code delegates the semantic question to a runtime that operates on real data. The model generates syntax; the computer supplies semantics.
The same model writes flawless Python and fabricates case citations. Python is a closed formal system where you can test whether the output works. Case law is an open system where meaning depends on interpretation, context, jurisdiction, and facts that exist outside any text the model has seen. The Hallucination rate tracks the syntax-semantics gap — and the gap tracks whether you can verify the output.
Why Legal Reasoning Doesn’t#
Legal language sits at the opposite end of the spectrum from code. An LLM can identify the holding in Loper Bright Enterprises v. Raimondo (2024) — the Court overruled Chevron deference. It can extract the vote count, classify the case, flag it as a landmark. All syntactic. Ask what Loper Bright means for a specific client’s regulatory challenge and you’ve crossed into semantics — and sometimes into territory where there’s no factual truth to find. What “waters of the United States” means under the Clean Water Act isn’t a fact about the physical world. It’s the output of a political process: which administration wrote the rule, which judges review it, which theory of statutory interpretation they hold. The six-justice majority and the three-justice dissent didn’t disagree about the words of the Administrative Procedure Act. They disagreed about what ambiguity itself means. What is ambiguous is itself an ambiguous question — a semantic dispute about the nature of semantic disputes that pattern-matching over legal text cannot resolve.
Ghosts, Animals, and World Models#
What makes an animal different from a ghost? An animal has a world model — an internal representation of reality built through interaction. A child doesn’t learn that fire is hot by reading about fire. She touches a stove. The experience builds a model: heat, pain, avoidance. That model grounds her understanding of the word “hot” in something the word refers to. Ghosts have words. Animals have models.
Three of the most credible researchers in AI are trying to build animals. Yann LeCun, Turing Award laureate, left Meta to launch AMI Labs with $1 billion in seed funding, calling LLMs a “dead end.” His alternative — world models using a JEPA architecture — learns representations of reality, not just the tokens that describe it. Fei-Fei Li, creator of ImageNet and co-founder of World Labs, is building spatial world models — AI that understands three-dimensional environments. “There’s no language out there in nature,” she’s said. “There is a 3D world that follows laws of physics.” Karpathy notes that LLMs display “amusingly jagged performance” — genius polymath on syntactic tasks, confused child on semantic ones — and argues for extracting the cognitive core from the memorization.
Three vocabularies, one claim: LeCun says build world models, Li says build spatial models, Karpathy says build animals. You can’t get from syntax to semantics by adding more syntax. The counterargument comes from the CEOs of the three largest LLM companies — Amodei, Altman, Hassabis — who’ve raised hundreds of billions on the premise that scaling the current paradigm works. LeCun, Li, and Karpathy have the freedom of not needing LLMs to be sufficient.
What This Means#
LLMs are extraordinary at processing legal language — extracting, classifying, comparing, reformatting text at a speed no human matches. The limitation shows up where the work stops being linguistic data processing and starts being about something. Code shows the boundary clearly: ask an LLM to count the r’s in “strawberry” and it fails; ask it to write code that counts them and it succeeds, because code has truth conditions you can check. Legal reasoning has no equivalent. No compiler tells you whether a statutory interpretation is true. No test suite catches a misapplied precedent. And sometimes there’s no determinate truth to find — the answer is the output of a political process, not a fact about the world.
The ceiling may not be permanent. LeCun, Li, and Karpathy are working on architectures that could close portions of the gap. But the current paradigm can’t resolve semantic questions that require Grounding it doesn’t have.
The strawberry test is a toy problem. But it demonstrates the right principle at exactly the right scale. The model couldn’t see the strawberry. It could only see the tokens. Every hallucinated case citation, every confidently wrong statutory analysis, every fabricated holding is the same mechanism on harder material — producing sentences that are syntactically flawless and may be semantically false. The model doesn’t know which are true. You do.
Further Reading#
- Animals vs. Ghosts. Karpathy’s essay on why LLMs are “summoning ghosts, not building animals” — the metaphor that frames this post.
- Why Do Large Language Models Struggle to Count Letters? Fu et al. (2024). Empirical study linking tokenization to character-level failures.
- LLM The Genius Paradox. Xu and Ma (2024). USC study on why math and coding reasoning don’t transfer to simple counting tasks.
- Hallucinating Law. Stanford RegLab on how LLM performance deteriorates as legal tasks require more semantic understanding.
- Large Legal Fictions: Profiling Legal Hallucinations in Large Language Models. Dahl et al. (2024). Systematic evaluation of hallucination rates across legal task types.
- Emergent World Representations: Exploring a Sequence Model Trained on a Synthetic Task. Li et al. (2022). The Othello-GPT paper — evidence that transformers can develop internal representations from pure token prediction.
- A Path Towards Autonomous Machine Intelligence. LeCun’s position paper on world models as the alternative to token prediction.
- Fei-Fei Li: AI Progress Now Depends on Physical Context. Li’s argument for spatial grounding.
- 2025 LLM Year in Review. Karpathy’s analysis of LLMs’ “jagged performance” and the ghost paradigm.
- Counting Ability of Large Language Models and Impact of Tokenization. Technical analysis of how tokenization schemes affect counting performance.
- Loper Bright Enterprises v. Raimondo. Cornell LII overview of the decision overruling Chevron deference.
This post is part of the Philosophy of AI series on LegalRealist AI. It is intended for informational and educational purposes only and does not constitute legal advice. AI capabilities described here reflect publicly available research as of the publication date. The syntax-semantics framework is presented as an analytical tool for evaluating AI output, not as a settled consensus in AI research — the question of whether scale or architectural changes will close the gap remains actively debated. Laws governing AI use vary by jurisdiction.