
TL;DR
- The government often holds the core transaction records before any investigation starts. Medicare claims, tax returns, PPP and EIDL applications — these records are submitted directly into federal systems. Fraud detection increasingly starts with a query, not a manhunt.
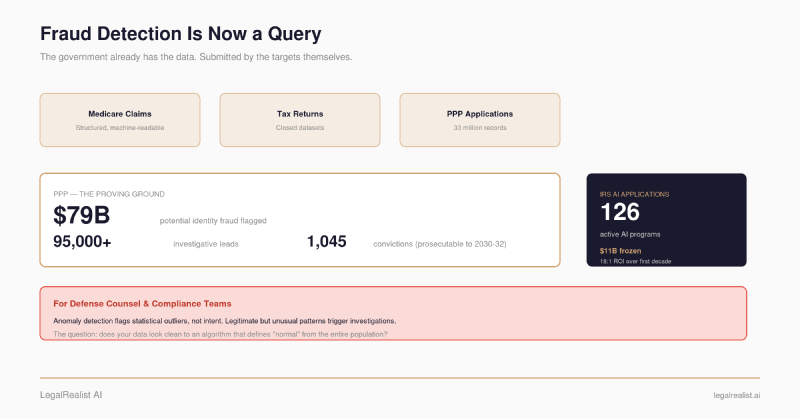
- Pandemic relief was the proving ground. Data scientists analyzed tens of millions of PPP and EIDL applications and cross-referenced Social Security numbers across agencies, flagging $79 billion in potential identity fraud.
- Healthcare fraud enforcement hit record scale in 2025. The DOJ’s annual takedown charged 324 defendants across $14.6 billion in alleged fraud — and credited proactive data analytics with catching a $10.6 billion scheme before most payments went out.
- The IRS has been using machine learning for pre-refund fraud detection for years. Its Return Review Program screens returns before refunds go out, while information-matching systems compare taxpayer filings against third-party forms such as W-2s and 1099s.
- Anomaly detection catches outliers, not intent. Providers and businesses whose billing or filings deviate from statistical norms can be flagged even when acting in good faith. Compliance programs need to understand what the algorithms are looking for.
Corrections & Updates
- June 24, 2026: Updated this post with 2025-2026 DOJ, CMS, GAO, PRAC, and IRS developments. The thesis was narrowed from “fraud detection is just a query” to the more defensible claim that structured first-party data lets enforcement start with a query, while linkage, legal authority, false positives, and proof remain the hard parts.
Federal prosecutors allege that a transnational criminal organization bought dozens of medical supply companies across the United States and submitted $10.6 billion in false Medicare claims for urinary catheters that were never delivered, using stolen identities from over one million Americans. The DOJ’s Health Care Fraud Unit Data Analytics Team detected the anomalous billing through proactive data analytics. CMS blocked all but $41 million of the $4.45 billion scheduled to be paid. The scheme — Operation Gold Rush, the largest healthcare fraud case ever charged — was caught not by a whistleblower, not by a patient complaint, but by analytics that noticed billing patterns that didn’t make sense. The defendants are presumed innocent unless proven guilty.
The government found this fraud in its own data — the Medicare claims it already collects, the billing patterns it already tracks, the enrollment records it already maintains. The federal government has spent the past five years building analytics infrastructure that treats its own structured data as an enforcement asset, cross-referencing billions of records across agencies to flag anomalies and generate investigative leads without waiting for anyone to report anything.
This post — the first in a series on data analytics and fraud enforcement — maps how three federal enforcement pipelines work: pandemic relief (the proving ground), healthcare (the largest target), and tax (the broadest reach). For defense counsel and compliance teams, the question is not only whether regulators have the data. It is whether your client’s patterns look normal, and whether you can explain the difference when they do not.
The Closed Dataset#
Call the first model what it is: the Bank Secrecy Act reporting model. Its dataset is FinCEN’s SAR database — 4.7 million Suspicious Activity Reports filed in FY 2024, over 12,000 per day. SARs contain structured fields and narrative components, and they remain central to financial-crime enforcement. But they are still human-triggered reports. The government receives them when a financial institution decides that activity looks suspicious enough to file.
The closed-dataset model is the opposite. Every Medicare claim is a structured digital record — procedure codes, dollar amounts, provider identifiers, patient identifiers, dates — submitted directly to CMS in machine-readable format. Every tax return is the same: income figures, deduction categories, employer IDs, all filed directly with the IRS. Every PPP loan application landed in the SBA’s systems with payroll numbers, employee counts, and Social Security numbers attached.
This is not perfectly clean data. PPP applications often lacked complete date-of-birth fields. Medicare claims have coding errors. Tax returns contain mistakes and ambiguities. Agencies also need legal authority, common identifiers, and data-sharing agreements before one database can be matched against another. But the records are structured, machine-readable, and already in federal systems, submitted by the very entities being scrutinized. Fraud detection increasingly starts with a query against data the government already holds. When CMS runs anomaly detection across 11 million daily Medicare claims, it is asking its own data: which billing patterns don’t look like the others?
The contrast with SARs matters because it explains why this enforcement model scales differently. A SAR requires a bank to notice, interpret, write, and file. A closed-dataset query can run across records the government already has. That does not make the output proof. It makes the output a lead.

What This Thesis Does Not Mean#
It does not mean the government’s data is clean. It does not mean agencies can freely share everything they hold. It does not mean anomalies prove fraud. It does not mean SARs, whistleblowers, subpoenas, interviews, and traditional investigative work are obsolete.
It means the starting point has changed. In programs built on structured filings and claims, the government can generate leads from first-party data before anyone complains. The hard work comes next: linking records across systems, separating legitimate outliers from bad actors, and turning statistical suspicion into admissible proof.
From “Pay and Chase” to “Detect and Deploy”#
For decades, federal fraud enforcement ran on a simple model: pay the claim, wait for a tip, investigate, and try to recover. The False Claims Act’s qui tam provision — which lets private whistleblowers file suits on the government’s behalf and collect a share of the recovery — was the primary enforcement engine. In FY 2025, whistleblowers filed a record 1,297 qui tam actions, and total FCA recoveries hit $6.8 billion, the highest in the statute’s history. Whistleblowers aren’t going away.
But the government is building a parallel track. Proactive data analytics — cross-referencing claims data, tax filings, enrollment records, and third-party databases using machine learning and anomaly detection — now generate enforcement leads independently of whistleblower tips. The DOJ-HHS False Claims Act Working Group, formed in July 2025, explicitly plans to use enhanced data mining to drive new investigative leads. CMS Administrator Dr. Mehmet Oz described the shift in March 2026: the agency is replacing the “pay and chase” model with a “detect and deploy” strategy that uses AI to identify fraud before payments go out.
Pandemic Relief Was the Stress Test#
The Paycheck Protection Program and COVID-19 Economic Injury Disaster Loan program were the largest fraud detection stress test in U.S. government history. PPP alone distributed approximately $800 billion in loans through over 5,000 lenders to more than 8 million borrowers — and did it at emergency speed, with self-certification and reduced internal controls. The speed that saved businesses also created the largest fraud surface the government had ever seen.
The Data Pipeline#
Phase 1: Screening (reactive, limited). The SBA built a four-step anti-fraud process that compared applications against public and private databases, ran data analytics, flagged applications for manual review, and referred likely fraud to its Office of Inspector General. But the full process wasn’t in place until more than half of program funds had already been distributed — over $525 billion in PPP loans approved before the screening was fully operational. The SBA’s machine learning tool focused on prioritizing loans with existing flags for human review rather than identifying new suspicious patterns, limiting its ability to catch complex fraud schemes.
Phase 2: Cross-agency analytics (the PACE model). Congress funded the Pandemic Analytics Center of Excellence (PACE), a centralized data analytics hub run by the Pandemic Response Accountability Committee (PRAC). PACE assembled 59 datasets with access to over 1.6 billion records from public, non-public, and commercial sources. Its data scientists did something the SBA couldn’t do alone: they cross-referenced PPP and EIDL applications against Social Security Administration records, HUD housing benefit applications, and other federal program data.
PACE analyzed 33 million PPP and EIDL applications and identified over 69,000 questionable Social Security numbers used to obtain $5.4 billion in pandemic loans and grants. Many of those SSNs were never issued by the SSA or didn’t match the names and dates of birth on the applications. A later analysis using random sampling across 67.5 million funded pandemic-relief applications estimated that approximately $79 billion in potential identity fraud could have been prevented with pre-award vetting.
PACE also compared income reported by PPP applicants against income reported to HUD for housing benefits — finding applicants who may have deliberately misrepresented their incomes to one program or the other. One such cross-agency analysis led to a large-scale criminal conspiracy case.
Phase 3: Knowledge graphs and lead generation. Private-sector analytics firms working with federal stakeholders built knowledge graph systems that mapped networks of control and ownership across PPP borrowers. These systems ingested raw loan data, enriched it with public records, watchlists, conviction databases, and commercial ownership datasets, then used entity resolution to connect duplicate or alias identities. The result: investigators could visualize networks — multiple loans tied to the same beneficial owner, unusually fast disbursement patterns, geographic clusters of suspicious applicants — rather than investigating loans one at a time.
An automated fraud detection tool built by eSimplicity for the SBA OIG identified over $200 billion in potential fraud and generated more than 95,000 leads, according to the vendor’s case study. That is useful evidence of scale, but it should be read as vendor-attributed, not an independent government performance audit.
The Enforcement Results#
As of January 2026, PACE had supported over 1,200 pandemic-related investigations involving more than 24,000 subjects and $2.5 billion in estimated fraud loss. The DOJ obtained more than 200 civil settlements and judgments totaling over $230 million for pandemic fraud in FY 2025 alone, bringing total civil recoveries to over $820 million. The enforcement pipeline is still active because Congress extended the statute of limitations for PPP and EIDL fraud to 10 years. A new category of enforcement actor has emerged: data-miner relators — private parties who use publicly available PPP loan data, corporate ownership records, and employment filings to identify potential FCA claims without any insider knowledge. They file qui tam suits based entirely on pattern analysis.
What PPP Proved#
Cross-agency data sharing catches fraud that siloed systems miss. An SSN that looks clean in the SBA’s database might belong to a deceased person in SSA records, or to someone reporting $600 in annual income to HUD while claiming an $875,000 monthly payroll to the SBA. Machine learning at scale generates leads that no human review team could produce. And the infrastructure built for pandemic oversight works for other programs. The PRAC urged Congress to make PACE permanent and expand its jurisdiction to all federal spending. Data-sharing agreements like the one between the SBA OIG and USDA OIG, signed in February 2026, signal that the cross-agency model is spreading.

Healthcare: The $6.8 Billion Enforcement Machine#
Healthcare fraud enforcement has used data analytics longer than any other federal domain — the CMS Fraud Prevention System has run machine learning against Medicare claims since 2011 — but the scale has changed dramatically.
The Data Fusion Center#
In June 2025, alongside the largest healthcare fraud takedown in history (324 defendants, $14.6 billion in alleged fraud), the DOJ announced the creation of a Health Care Fraud Data Fusion Center. The Fusion Center brings together the DOJ’s Health Care Fraud Unit Data Analytics Team, HHS-OIG, the FBI, and other agencies to use cloud computing, AI, and shared analytics platforms. Its stated purpose: break down information silos and enable rapid prosecution of emerging fraud schemes. The initiative implements Executive Order 14243, “Stopping Waste, Fraud, and Abuse by Eliminating Information Silos.”
CMS launched its own Fraud Defense Operations Center (FDOC) in 2025. By March 2026, it had triaged more than 340 suspect providers and prevented over $1.4 billion in potential payments while investigations continued. CMS estimates it prevented $11.9 billion in potentially fraudulent Medicare payments from FY 2022 through 2024.
How the Analytics Work#
CMS analyzes Medicare fee-for-service claims on a streaming, nationwide basis — processing over 11 million pre-paid claims daily. The system flags billing spikes, geographic anomalies, and provider-level outliers. When patterns deviate from norms, CMS can suspend payments, revoke billing privileges, or refer cases for investigation.
The Operation Gold Rush case from the opening of this post shows how this works. The Data Analytics Team spotted anomalous billing from newly acquired DME companies whose billing volume didn’t match normal provider behavior. CMS froze the payments before they went out. In March 2026, CMS imposed a six-month nationwide moratorium on new DME supplier enrollment and revoked billing privileges for 5,586 providers and suppliers.
The Fusion Center also enables what individual agencies couldn’t do alone: connecting billing anomalies in Medicare data with prescribing patterns tracked by the DEA, complaint data from state attorneys general, and financial transaction patterns flagged by law enforcement. As Blank Rome’s analysis notes, the government’s data-driven approach detects anomalies, not intent — meaning providers whose practices differ from regional or national averages may be identified as outliers even when the variation reflects legitimate clinical specialization, patient demographics, or innovative care models.
The FCA Pipeline#
Healthcare accounted for over $5.7 billion of the $6.8 billion in FCA recoveries in FY 2025. The DOJ-HHS Working Group explicitly plans to use enhanced data mining to drive new investigative leads — shifting the mix from whistleblower-initiated to government-initiated FCA actions. Data analytics was deployed successfully for PPP fraud, and the government is now expanding that playbook to healthcare.
CMS also launched the Wasteful and Inappropriate Service Reduction (WISeR) Model in January 2026 — a voluntary program in six states that uses AI, machine learning, and human clinical review to introduce prior authorization requirements for services historically associated with fraud and inappropriate utilization. It’s the first CMS program designed to use AI to prevent waste before claims are paid, rather than recovering funds after.
The IRS Cross-References Returns#
Tax is the broadest version of the same pattern. The Return Review Program (RRP), the IRS’s primary system for pre-refund fraud detection, uses supervised and unsupervised machine learning to flag suspicious returns before refunds are issued. From 2015 through 2019, the RRP permanently froze nearly $11 billion in refunds, producing an 18:1 return on investment over its first decade.
The core mechanism is cross-referencing. The IRS matches reported income against W-2s, 1099s, and other third-party information returns. When what a taxpayer reports does not match what an employer, broker, platform, or payer reported, the mismatch can trigger automated notices, refund holds, or audit selection. Machine learning changes the scale of that process: instead of selecting returns only through fixed rules or random samples, models can prioritize returns and issues by predicted noncompliance risk.
For complex cases, the IRS has also used analytics and AI-assisted selection to target large partnerships and high-income taxpayers. In 2023, for example, the agency announced compliance efforts involving 75 large business partnerships with roughly $10 billion in average assets, alongside high-dollar collection cases against millionaires. Those efforts matter here because partnership returns, like Medicare claims, are structured filings: the government can compare reported positions across entities, partners, and years before deciding where to send human auditors.
The same logic applies when pandemic-relief applications are compared with payroll tax filings. A business that claimed a large payroll to SBA but reported minimal payroll taxes to the IRS creates a discrepancy investigators can test. The discrepancy is not proof of fraud. It is the beginning of the inquiry.

What This Means for Defense Counsel and Compliance Teams#
Your client’s data is often the first witness. Before an agent knocks on the door, analytics may already have compared your client’s billing, filings, or applications against peers in the dataset. The investigation may begin with a statistical anomaly, not a complaint. Defense counsel should understand what normal looks like in their client’s billing category — because the government’s analytics team may already be looking at the same comparison. As one analysis put it, providers whose practices differ from statistical norms may be flagged regardless of whether the variation reflects legitimate clinical judgment.
Cross-agency data sharing weakens the old silos. The government that struggled to connect SSA data to SBA loan applications in 2020 now has stronger incentives and more institutional infrastructure to do it. Information-sharing agreements between agencies mean that a discrepancy in one dataset — an SSN mismatch, an income inconsistency, a billing outlier — can trigger scrutiny across multiple programs. Compliance teams should follow the government’s lead in a narrower, practical sense: reconcile the data they already submit across programs before the government does it for them.
The question for compliance teams isn’t whether your data is clean in the abstract. It’s whether the data you already submitted — the claims, the returns, the applications — tells a consistent story when compared against peer filings and other government records.
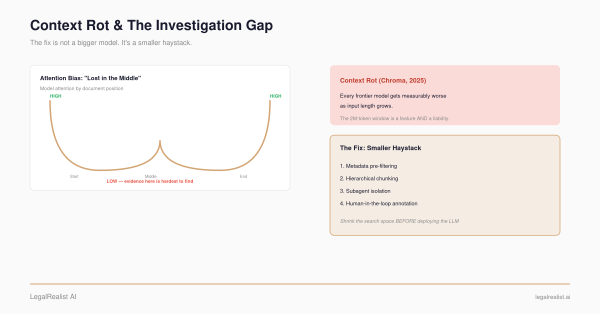
Next in this series: how specific analytics techniques — anomaly detection, network analysis, predictive modeling, and natural language processing — actually work, and what each one can and can’t catch.
Further Reading#
- PRAC Pandemic Analytics Center of Excellence (PACE). The cross-agency data analytics hub supporting pandemic fraud investigations.
- National Health Care Fraud Takedown 2025. DOJ’s announcement of the largest healthcare fraud enforcement action in history.
- GAO: Medicare — CMS’s Use of Data Analytics to Identify and Prevent Fraud. March 2026 report on CMS’s data analytics and $11.9 billion in prevented payments.
- GAO: Improved Controls Needed for Referring Likely Fraud in SBA’s Pandemic Loan Programs. March 2025 report on SBA’s four-step anti-fraud process and its limitations.
- The Expanding Risk Landscape: DOJ’s Advanced Data Analytics and the Healthcare Fraud Data Fusion Center (Blank Rome). Analysis of false-positive risks in data-driven enforcement.
- DOJ Continues False Claims Act Enforcement of PPP Loans Into 2026 (Winston & Strawn). Analysis of the data-miner relator phenomenon.
- DOJ’s Record-Breaking 2025 False Claims Act Recoveries (White & Case). Breakdown of the $6.8 billion FCA year.
- From Innovation to Regulation: Health Care Enforcement Related to AI (Mintz). Practical guidance on using the government’s own AI tools for compliance.
- Machine Learning and Tax Enforcement (Urban Institute). Academic analysis of the IRS Return Review Program’s machine learning approach.
This post is part of the Data Analytics and Fraud series on LegalRealist AI. It is intended for informational and educational purposes only and does not constitute legal advice. Enforcement statistics, agency capabilities, and regulatory programs described here reflect publicly available information as of the publication date and are subject to change. Laws governing fraud enforcement vary by jurisdiction and program.


{kind=link}
{kind=link}
{kind=link}
{kind=link}